Chapter 9
Searching consensus
Initial version: 2024-03-19
Last update: 2025-05-28
Table of contents
- Consequences of message passing imperfections
- Searching consensus, part I: The longest chain criterion
- Searching consensus, part II: Chainwork – the heaviest chain criterion
- Chainwork calculations explained
- Implementing chainwork in our case
- Summary
Consequences of message passing imperfections
In the previous chapter you have seen that despite the fact that all nodes acts independently and are not centrally controlled and synchronized according to one common timer, the message flow determines their rhythm of life (see chapter 8: Cheating doesn't pay off, section: Competition rules – the heartbeat that synchronizes all nodes). The arrival of a new message to node is the clock-pulse that governs the work of each node. However, the switch between the two phases does not take place exactly at the same absolute time for all the nodes. This is due to all transmission issues that can occur: messages may arrive in any order, may be delivered with time delay, or simply may get lost:
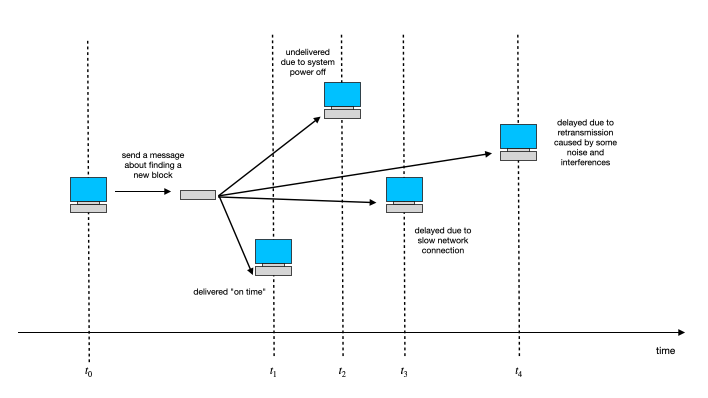 |
| Figure: Network influence on message delivery |
In consequence every node does not have identical information at its disposal. In such conditions a real challenge is to assure identical outcomes when clarifying ownership requests. The time is the essence of this issue. The least certain is to refer to messages from not very distant history. The older message is, the more probable that part of the chain build on it is correct. So when ownership is resolved, you should recall facts from history which are "guarantee" to be correct. Correct, means: is the same in every node. So it must belong to the common "core" but possibly with different latest history.
Now you will see how to build on every node the blockchain tree with the same correct trunk you can really rely on and possibly various divergences on the latest, uncertain, history. With the passage of time, all different alternate histories (blockchains) eventually converge the one, identical for all nodes, version of the history.
To make my explanation more understandable, I will divide my description into two parts, where second part is an extension of the first part.
Searching consensus, part I: The longest chain criterion
As you know, to add a new block to the blockchain you need to use pretty much processing power solving cryptographic puzzle (proof of work), which means that every block on the blockchain used up energy to get there. Energy costs money, and it's not cheap at all.
Therefore, a chain with more blocks in it will have taken more energy to build it than a chain with fewer blocks in it, and as a rule nodes will always adopt this chain over a shorter one. Why? If there are two chains and one of them is longer, it must be correct. Must be correct, because none would invest into forging historic block and developing invalid chain. Certainly you can imagine scenarios when one would take on such a challenge but in such case, starting from some block one must:
- Forge historic block.
- Recalculate all subsequent blocks.
- Catch up with the current block.
- Significantly overtake the current block to create the longest chain.
It is not impossible but certainly it would require a lot of computing power – it would cost a lot of money. Even if you make this effort for reasons known to you, it still won't be enough to introduce a forged block into the chain – I will explain this in the tutu .
Saying in simple words, the longest chain is the most expensive. In consequence, to allow every node on the network to agree on what the blockchain looks like, and therefore agree on the same blocks history, the choice of adopting by nodes the longest chain of blocks seems to be quite natural.
It was a theory, now you will see how it actually works in an example.
Initial case
Consider an initial situation where all nodes maintain and agree on the identical version of the blockchain, as depicted in figure below:
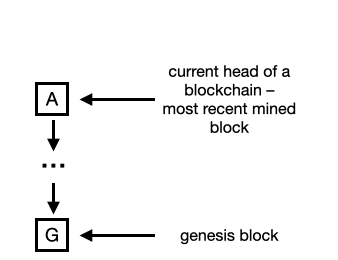 |
| Figure: Initial blockchain states; all nodes maintain the same chain of blocks |
Each of the boxes on this figure represents one block of the blockchain. The arrow that points from one box to another represents the hash reference that links a block header to its predecessor. The genesis block is the first blok "initializing" blockchain structure [gb]. It is almost always hardcoded into the software of the applications that utilize its blockchain. It is a special case in that it does not reference a previous block and or does not have any useful data.
In this initial situation, all nodes agree on one common history of the data and try to extend the existing chain with another block that refers to the current head block (block
A) as its predecessor. Miners will attempt to solve the puzzle until they hear a winner is declared.
Fork case
A fork is simply an occurrence of a disagreement about the sequence of blocks, either their order or their presence or absence. When such a disagreement occurs, the chain splits into two which is called a fork. Each fork forms independent, and up to a certain moment equivalent, chain so miners are free to pick which one to apply their work on. Such a fork may be an effect of more than one "winner" at the same time or delayed block mined message. Fork is not an unusual situation but rather very common case and occurs almost all the time. It may be also depicted as a tree:
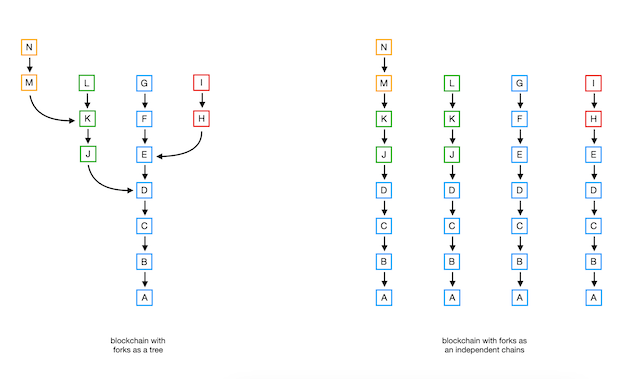 |
| Figure: Blockchain and forks: left: in the form of tree; right: in the form of independent chains (each chain is maintained by different node) |
Scenario 1: more than one "winner" at the same time
Scenario 2: delayed block mined message
G1 on the figure below). However, sending a new block through a network needs time and may be exposed to various sort of obstacles resulting in the delay of the message, the need to retransmit it or its complete loss. In result some of nodes (denoted as G2 on the figure) do not received this message and still try to extend the chain from initial case (as it is the only chain they know). Eventually, one of G2 nodes successfully solves the hash puzzle for a new block.
Regardless of the scenario (probably you can imagine other possibilities but reasoning would be the same for all cases) you have two groups
G1 and G2 with different chains:
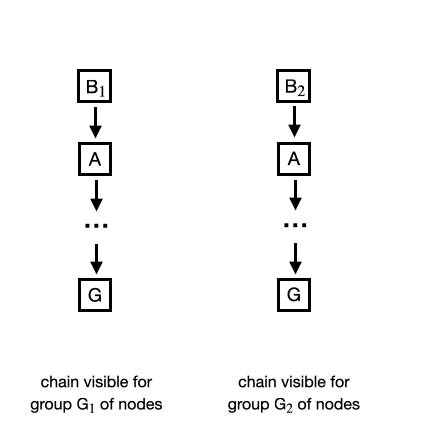 |
| Figure: Initial phase of the chain fork |
Eventually, thanks to data exchanging informations among peers, all nodes will receive both blocks: block
B2 will be delivered to all nodes in group G1 and block B1 will be delivered to all nodes in group G2. The chain splits and this is how fork comes into being. Now the blockchain consists of two branches on top of a common trunk:
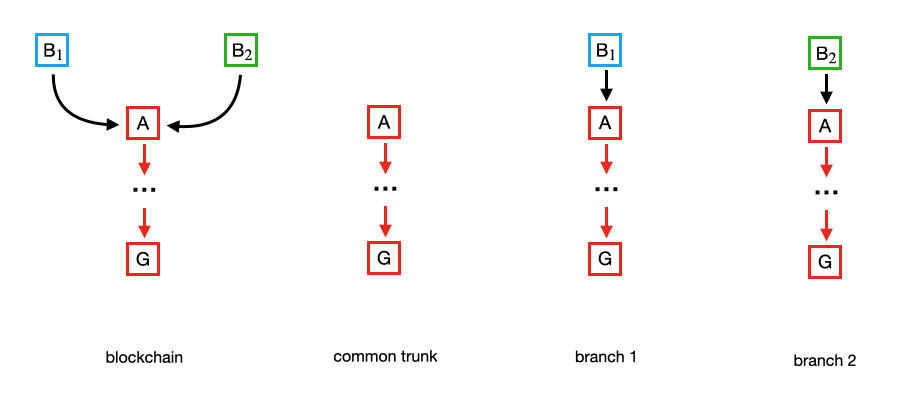 |
| Figure: Chain with forks |
At this moment there is no method to resolve unambiguously which chain is "better" because both chains have the same length and so are consider to be equivalent and they are just as true. In consequence nodes are free to decide which branch to extend.
Resolve case
All peers do their best to solve the next puzzle. Assume that one of them did his job and none of the previous scenarios take place. The winner may add new block that refers either to block
B1 or B2 as its predecessor. Assume that it selected branch with block B1 and add at the top of it new block, block C:
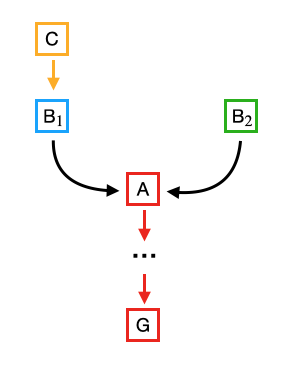 |
| Figure: Resolving chain fork, part I |
This fact is propagated throughout messages to all other nodes. If message reaches other nodes before any other new block message, such nodes will reorganize its blockchain structure leaving only the longest chain:
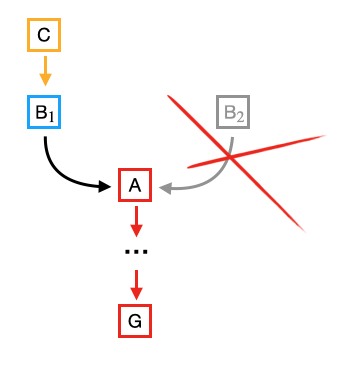 |
| Figure: Resolving chain fork, part II |
Searching consensus, part II: Chainwork – the heaviest chain criterion
The idea behind the longest chain criterion is to use the chain of blocks that took the most effort to build. Quite natural seems to be that the longer chain is, the more effort it required, so it must be more reliable. Due to the proof of work, adding a new block is computationally expensive and makes attempts to manipulate the block already placed in the chain even more computationally expensive. The enormous cost is what stops other from forgery by making any manipulation unprofitable.
For the most of the time longest chain criterion is valid, at least as long as you don't change difficulty level of the cryptographic puzzle which nodes try to solve. However, difficulty changes through time when blocks are mined faster or slower than every fixed amount of time (for example 10 minutes in Bitcoin) on average. In consequence some blocks are going to require more or less energy to mine than others and the chain that required the most energy (is the most expensive) to build is not necessarily the one with the most blocks in it.
Why changing difficulty level
Changing the difficulty you ensure that blocks with data are added to the blockchain at close to regular intervals, regardless of the general condition of the system. We have discussed this topic in chapter 7: Difficulty and target.
Chainwork
$$2016 \cdot 10 [\textrm{min}] = 20160 [\textrm{min}]$$
$$[\textrm{day}] = 60[\textrm{min}] \cdot 24 = 1440[\textrm{min}]$$
$$20160[\textrm{min}]/1440[\textrm{min}] = 14 [\textrm{days}] = 2 [\textrm{weeks}]$$.
So in each two week slot difficulty stays the same, so every new block requires in average the same amount of effort to mine, and therefore adds the same amount of effort or work to the chain. In the image below times $t_1$, $t_2$, $t_3$ are not the same, but very close:
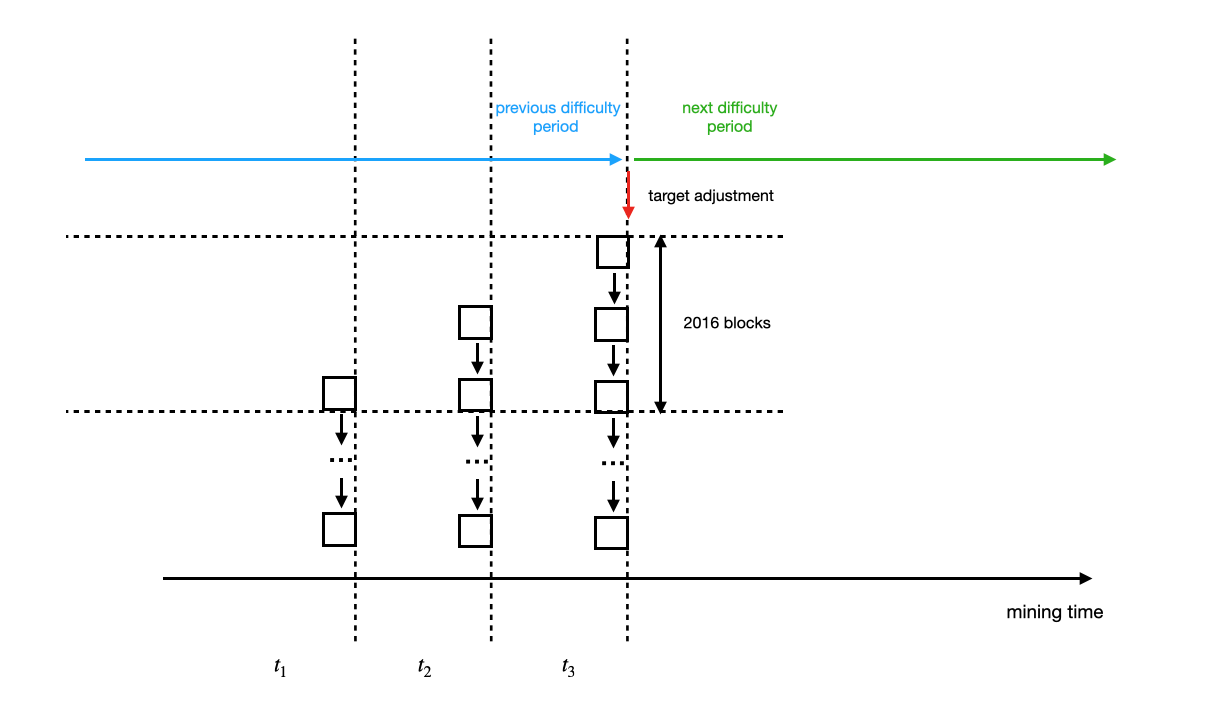 |
| Figure: Similar time-slots case: mining each new block required close to others amount of time |
In such situation the longest chain criterion, as it was discussed so far, works perfect.
However, nodes are not perfectly synchronized and in effect multiple alternative chains appear. Some of them may adjust difficulty some other may not do this or adjust with different factor. In consequence, for one chain difficulty may be increased while for other stay unchanged which will make mining unfair – one chain will grow faster (or slower) than other:
 |
| Figure: Different time-slots length as an effect of different difficulty adjustment |
In this case adopting the chain with more blocks doesn't mean adopting the chain required more work to build it. This is why the "longest chain" is not determined by the pure number of nodes metric but by a metric called chainwork. You may think about it as measuring size of the chain (longest chain) versus measuring its weight (chainwork).
Technically speaking, chainwork for one block is the number of computed hashes that are (or was) expected to have been necessary to add this block to the blockchain. The (total) blockchain chainwork, the chain's weight, is the sum of chainwork of all present blocks and expressed the amount of work needed to add all blocks included in blockchain. Blockchain store this value in each block's header in the field
chainwork. So when you start to mine new block you have to set up this field with the value:
chainwork = accumulated_chainwork + expected_chainwork
accumulated_chainworkis the sum of all chainworks of all previous, successfully added, blocks and is equall tochainworkfield of previous block;expected_chainworkis an expected chainwork for current block you are going to mine.
Summing up
Now you know what a chainwork is, how you should calculate it and why use the heaviest chain criterion instead of a simple the longest chain criterion.
The most important idea behind it is to rate somehow the speed at which nodes add new blocks to the blockchain. If creation speed is limited, natural choice of "truthiness" is length of a chain, because it describes a total time (aggregated time) needed to create this chain. And this time would be needed if someone would like to recompute this chain one day. If all nodes have the same performance, aggregated time is equivalent to aggregated energy and in consequence determines the cost of chain's computations.
However, the constant computing time, resulting in the longest chain criterion, is only a theoretical assumption. In practice, this time may vary even significantly from node to node, from block to block.
Hence, the amount of aggregated computational effort, resulting in the heaviest chain criterion, spent on creating a blockchain seems to be a natural alternative for selecting a branch of chain in the case that more than one conflicting version exist.
The commonly used phrase longest chain refers to the blockchain that has taken the most energy to be build. For the most of the time it is equivalent to the chain with the most blocks in it, but to be more precise it is always the chain with the most amount of work in it.
Chainwork calculations explained
Expected chainwork in simple case
To understand how expected chainwork works consider simplified (but not to much) case. Say you are randomly generating numbers between 1 and 100 as long as you generate number below your target which is 4. How many numbers, on average, would you need to generate before you get one conforming your requirements? In theory you need:
$$ 100/4 = 25 $$
tries. So on average you will need to generate 25 numbers to get one that is below 4. Let's verify this with the following simple code:
import random
numberOfTests = 10
target = 4
totalTries = 0
for t in range(numberOfTests):
tries = 0
while True:
tries += 1
v = random.randint(1, 100)
if v < target:
break
totalTries += tries
print(f"try {t}: tries={tries}, totalTries={totalTries}, average={totalTries/(t+1)}")
try 0: tries=33, totalTries= 33, average=33.0
try 1: tries=68, totalTries=101, average=50.2
try 2: tries= 3, totalTries=104, average=34.7
try 3: tries=72, totalTries=176, average=44.0
try 4: tries=21, totalTries=197, average=39.4
try 5: tries=19, totalTries=216, average=36.0
try 6: tries= 5, totalTries=221, average=31.6
try 7: tries= 6, totalTries=227, average=28.4
try 8: tries=15, totalTries=242, average=26.9
try 9: tries= 4, totalTries=246, average=24.6
try 0: tries= 38, totalTries= 38, average=38.0
try 1: tries= 50, totalTries= 88, average=44.0
try 2: tries= 48, totalTries=136, average=45.3
try 3: tries= 12, totalTries=148, average=37.0
try 4: tries= 48, totalTries=196, average=39.2
try 5: tries= 41, totalTries=237, average=39.5
try 6: tries= 7, totalTries=244, average=34.9
try 7: tries= 54, totalTries=298, average=37.3
try 8: tries=212, totalTries=510, average=56.7
try 9: tries= 50, totalTries=560, average=56.0
How does it control time between blocks? In my case, assuming I am only able to generate a number between 1 and 100 once a second, this should take me 25 seconds in average. Of course it is not going to be 25 seconds every time because I could get lucky even with the one of the first numbers I generate (see try 2 in first session above). On the other hand there can be a case required much more tries (see try 8 in second session). But over the long run I will obtain 25-second intervals separating every number below my target.
Anyway, exactly the same kind of calculation takes place in Bitcoin, but just with bigger numbers (and usually represented in hexadecimal).
Expected chainwork in our case
As you know from previous part, the process of mining involves hashing a block header. Every time you perform a hash, you obtain a number with exactly the same number of (hexadecimal) digits (at least as long as you don't change hashing function). In our case the
sha256 was used so you received a 256-bit number, which could be any integer between 0 and 32-digit hexadecimal number (I add spaces every eight digits to make clear the number):
0xffffffff ffffffff ffffffff ffffffff ffffffff ffffffff ffffffff ffffffff
0x000000ff ffffffff ffffffff ffffffff ffffffff ffffffff ffffffff ffffffff
0xffffffff ffffffff ffffffff ffffffff ffffffff ffffffff ffffffff ffffffff
divide by:
0x000000ff ffffffff ffffffff ffffffff ffffffff ffffffff ffffffff ffffffff
equals:
0x1000000
0x1000000 (which is 16777216 in decimal) hashes on average to get a result below the assumed value. And this will be the chainwork for a block with difficulty equals to 6. By the way, please note how this theoretical value is close to the value you obtain making a test in a chapter 3: Data fingerprinting, section: Proof of work – solving a hash puzzle – compare with a table you have at the end of this section (see row for difficulty = 6).
Chainwork in Bitcoin case
As you know from chapter chapter 7: Difficulty and target in case of Bitcoin in the block header of every block you can find the
difficulty field and the bits which stores the target in compact representation. The maximum value for target in Bitcoin is defined as 1D00FFFF which written in full size form looks as it given below:
0x00000000FFFF0000000000000000000000000000000000000000000000000000
$ bitcoin-cli getblockhash 0
000000000019d6689c085ae165831e934ff763ae46a2a6c172b3f1b60a8ce26f
$ bitcoin-cli getblockheader 000000000019d6689c085ae165831e934ff763ae46a2a6c172b3f1b60a8ce26f
{
...
"height": 0,
...
"bits": "1d00ffff",
"difficulty": 1,
"chainwork": "0000000000000000000000000000000000000000000000000000000100010001",
...
}
1 and target (via bits field) equal to maximum possible value, that is 1D00FFFF which agrees with the formula I presented in chapter 7:
target = targetMax / difficulty
0x100010001? Because in this case target is equal to targetMax thus chainwork should be equal to 1 as a quotient of targetMax divided by target. However such a calculation wouldn't be true, wouldn't describe true effort. Why? Because hash you obtain for every block are not limited to targetMax but belongs to whole 32-bytes interval starting at:
hashMin = 0x0000000000000000000000000000000000000000000000000000000000000000
and ending at:
hashMax = 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
targetMax is limited from above and despite target = targetMax not every hash is lower or equal to targetMax (but is lower or equal to hashMax). Thus to get chainwork you should divide hashMax by targetMax:
0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
/
0x00000000FFFF0000000000000000000000000000000000000000000000000000
=
0x1.000100010001... x 16^8
=
0x100010001.0001...
0x0000000000000000000000000000000000000000000000000000000100010001
1 (you can call it a base cost):
difficulty '1' = chainwork '0x100010001'
Each time when a new block is generated, you set its
chainwork as a sum of accumulated_chainwork, which is a chainwork field of previous block, and expected_chainwork, which is an expected chainwork for current block, that is 0x100010001.
The Genesis Block were added to the Blockchain with timestamp
03 Jan 2009, 18:15:05 and target mentioned above. As you know, the target adjusts every 2016 blocks, however in case of Bitcoin the first effective adjustment had place for the 17th block session, started at block 32256 on 30 Dec 2009, 06:11:04 (see Learn me a bitcoin. Target or Learn me a bitcoin. Explorer):
Block Target [hex] Date [UTC]
32256 00000000d86a0000000000000000000000000000000000000000000000000000 30 Dec 2009, 06:11:04
30240 00000000ffff0000000000000000000000000000000000000000000000000000 18 Dec 2009, 09:56:01
28224 00000000ffff0000000000000000000000000000000000000000000000000000 27 Nov 2009, 21:51:07
26208 00000000ffff0000000000000000000000000000000000000000000000000000 31 Oct 2009, 15:28:20
24192 00000000ffff0000000000000000000000000000000000000000000000000000 02 Oct 2009, 03:27:08
22176 00000000ffff0000000000000000000000000000000000000000000000000000 04 Sep 2009, 13:01:38
20160 00000000ffff0000000000000000000000000000000000000000000000000000 25 Jul 2009, 00:30:16
18144 00000000ffff0000000000000000000000000000000000000000000000000000 26 Jun 2009, 21:32:53
16128 00000000ffff0000000000000000000000000000000000000000000000000000 31 May 2009, 02:31:25
14112 00000000ffff0000000000000000000000000000000000000000000000000000 12 May 2009, 03:20:25
12096 00000000ffff0000000000000000000000000000000000000000000000000000 24 Apr 2009, 18:51:38
10080 00000000ffff0000000000000000000000000000000000000000000000000000 06 Apr 2009, 22:04:23
8064 00000000ffff0000000000000000000000000000000000000000000000000000 20 Mar 2009, 00:26:26
6048 00000000ffff0000000000000000000000000000000000000000000000000000 02 Mar 2009, 04:01:53
4032 00000000ffff0000000000000000000000000000000000000000000000000000 12 Feb 2009, 19:16:30
2016 00000000ffff0000000000000000000000000000000000000000000000000000 27 Jan 2009, 13:38:51
0 00000000ffff0000000000000000000000000000000000000000000000000000 03 Jan 2009, 18:15:05
$ bitcoin-cli getblockhash 32255
00000000984f962134a7291e3693075ae03e521f0ee33378ec30a334d860034b
$ bitcoin-cli getblockheader 00000000984f962134a7291e3693075ae03e521f0ee33378ec30a334d860034b
{
...
"height": 32255,
...
"bits": "1d00ffff",
"difficulty": 1,
"chainwork": "00000000000000000000000000000000000000000000000000007e007e007e00",
...
}
0x7e007e007e00, which is exactly the height 32255+1(+1 for the Genesis Block because blocks in Bitcoin started counting from 0) times 0x100010001:
(32255+1)_10 x 100010001_16 = 7e007e007e00_16
0x7e007e007e00. Now let's take a look at block 32256:
$ bitcoin-cli getblockhash 32256
000000004f2886a170adb7204cb0c7a824217dd24d11a74423d564c4e0904967
$ bitcoin-cli getblockheader 000000004f2886a170adb7204cb0c7a824217dd24d11a74423d564c4e0904967
{
...
"height": 32256,
...
"bits": "1d00d86a",
"difficulty": 1.182899534312841,
"chainwork": "00000000000000000000000000000000000000000000000000007e01acd42dd2",
...
}
difficulty has changed from 1.0 to 1.182899534312841. If you calculate chainwork for this block you obtain:
[chainwork including block 32256] = [previous chainwork value] + [expected chainwork for block 32256]
[previous chainwork value] = [accumulated chainwork up to block 32555] = 0x7e007e007e00
[expected chainwork for block 32256] = [difficulty] * [base cost]
= 1.182899534312841 * 0x100010001
= 0x12ed3afd2.03999..._16
= (approx) 0x12ed3afd2
[chainwork including block 32256] = 0x7e007e007e00 + 0x12ed3afd2 = 0x7e01acd42dd2
0x7e01acd42dd2 included in this block.
Implementing chainwork in our case
Simple definition of
difficulty (number of leading zeros) in our case results that target is much more difficult to control (see Adjusting target with difficulty in our blockchain section in chapter Difficulty and target). However it is a good exercise for testing our understanding of the topic if you try to implement chainwork for our difficulty. So, let's do it.
As you know from that chapter, controlling difficulty by the number of leading zeros is much more discreet – you have very limited number of different difficulty levels. In result you will have a limited number of expected chainwork values. From the preceding section of this chapter, Expected chainwork in our case you know that cost of
difficulty=6 is equal to:
0xffffffff ffffffff ffffffff ffffffff ffffffff ffffffff ffffffff ffffffff
divide by:
0x000000ff ffffffff ffffffff ffffffff ffffffff ffffffff ffffffff ffffffff
equals:
0x1000000 (which is `16777216` in decimal)
expected chainwork
diff. hexadecimal decimal
1 0x10 16
2 0x100 256
3 0x1000 4096
4 0x10000 65536
5 0x100000 1048576
6 0x1000000 16777216
7 0x10000000 268435456
8 0x100000000 4294967296
9 0x1000000000 68719476736
10 0x10000000000 1099511627776
Summary
In this chapter you have seen that what you call a blockchain you should rather call blocktree or blockchains. Why you don't do that? Because blocktree or multiple alternative blockchains is only a transient stage on the way of searching consensus – one and only one blockchain which you can use as a single source of truth.
The blocktree consists of all valid blocks whose entire ancestry is known, up to the genesis block – the very first block of a given blockchain. At every given time you use only one branch (representing one of conflicting versions of the history of blocks), called active chain, which is a path from tree's root (genesis block) to the leaf node representing block you treat as the newest (the most recently added). Every such path is a valid choice, but nodes are expected to pick the one with the most work in it based on chainwork criterion.
Such a choice makes every attempt of forgery very, very expensive (in terms of hardware, time and money) and thus deterring potential criminals trying to change history of blocks.