Nauki, Techniki i Sztuki w Łodzi
www.festiwal.lodz.pl
| Blok tematyczny: | Za pan brat z matematyką i informatyką |
|---|---|
| Rodzaj imprezy: | wykład, pokaz |
| Data: | 18.04 |
| Godzina rozpoczęcia: | 10:00 |
| Godzina zakończenia: | 10:45 |
| Opis imprezy: | Nie zmywa, nie tańczy i nawet trawy nie kosi. Jest na to zbyt mały. Jednak pomimo niewielkiego wzrostu, z ochotą porusza się w świecie ludzi badając każdy zakamarek. Jeśli interesuje Ciebie jak zbudować mały robot kołowy, jak sprawić by widział i myślał - zapraszamy na wykład. |
| Adresaci imprezy: | licealiści |
| Organizator: | Wydział Matematyki i Informatyki UŁ |
| Miejsce: | Wydział Matematyki i Informatyki Uniwersytetu Łódzkiego, Banacha 22, Łódź, D202 |
| Prowadzący: | dr Fulmański Piotr, mgr Jastrzębski Krzysztof |
Część I: co i jak chcemy zrobić oraz ważne pytanie.
Prowadzimy nasze doświadczenia nie tyle aby rozwiązać problem - to zwykle jest proste - ale aby zrozumieć pewne procesy. Zrozumieć jakie czynniki i w jakich sytuacjach wpływają na podjęcie przez człowieka konkretnych decyzji. Dlatego
Problem który jest przedmiotem naszego zainteresowania można zawrzeć z takim temacie
Założenia jakie nam przyświecają omówiliśmy na wykładzie w ramach XI edycji Festiwalu (prezentacja z XI Festiwalu, 2011):
Posługiwanie się obrazem jest tutaj bardzo istotnym założeniem, które o dziwo znacznie utrudnia rozwiązanie zdania (można powiedzieć, że bogatsza informacja powoduje większe problemy - im więcej wiem, tym moje problemy są poważniejsze - filozoficzne wiem, że nic nie wiem przypisywane Sokratesowi).
Oczywiście nie o samo rozwiązanie zadania tutaj chodzi, gdyż ono samo w sobie jest banalne. Tak banalne rozwiązanie nie pozwala nam zrozumieć istoty procesów widzenia, a więc nie pozwala nam uogólnić wyniku. Jako uogólnienie rozumiemy tutaj opracowanie takiego sposobu postępowania, które pozwoli nam łatwo przejść np. od małego robota mobilnego do sterowania pełnowymiarowym pojazdem kołowym (samochodem) po normalnych drogach.
W ramach XI edycji Festiwalu pokazaliśmy pewne podejście, które daje się uogólnić (film z XI Festiwalu, 2011). Podeście to opierało się na założeniu, że mamy możliwość ,,wycięcia'' z obrazu tylko tego co jest drogą. W tym roku próbowaliśmy skupić się na samym procesie ,,wycinania'', tzn. znaleźć odpowiedź na pytanie, jak to się dzieje, że coś (pewien fragment obrazu) klasyfikujemy jako obszar po którym możemy się poruszać a w ogólności:
Poszukując odpowiedzi na to pytanie będziemy chcieli w jakimś stopniu naśladować nasz zmysł wzroku. Najpierw jednak musimy go zrozumieć.
Część II: próbujemy zdać sobie sprawę ze stopnia trudności postawionego zadania.
Próbując znaleźć odpowiedź na postawione pytanie musimy stać się jak komputer - jak komputer, czyli jak ktoś/coś kto NIC nie wie! Komputery nie są ani mądre ani inteligentne - to, co najwyżej, ludzie którzy ich używają tacy są.
Wyobraźmy sobie taki obraz.
![]()
Co on przedstawia? Jedna z odpowiedzi jaka padnie to zapewne: korytarz. Dlaczego właśnie to? Pewnie dlatego, że mamy w głowie ,,zakodowany'' pewien wzorzec korytarza, który właśnie tak wygląda. Dlaczego jako odpowiedź nie padnie: ostrosłup ścięty oglądany z góry? Zapewne dlatego, że zwykle częściej mamy do czynienia z korytarzem niż z ostrosłupem ściętym - częściej używamy tego pierwszego określenia niż drugiego.
Dobrze, powiedzmy, że jest to korytarz. Pytanie jest następujące: gdzie jest podłoga a gdzie sufit i dlaczego? Proszę wskazać...
A na obróconym rysunku - gdzie jest?
![]()
Nie wiemy. Nie mamy żadnych punktów orientacyjnych. Czym są punkty orientacyjne? To coś co znamy - w szczególności znamy właściwości fizyczne.
Załóżmy jednak, że punktów takich brak (mówiąc bardziej precyzyjnie: brak czegoś co znamy), ale wiemy trochę więcej - można powiedzieć, że widzimy więcej, ale czy to nam pomaga?
![]()
A jeśli dołożymy tekstury
![]()
![]()
Zróbmy zatem jeszcze jedną modyfikację - co teraz możemy powiedzieć?
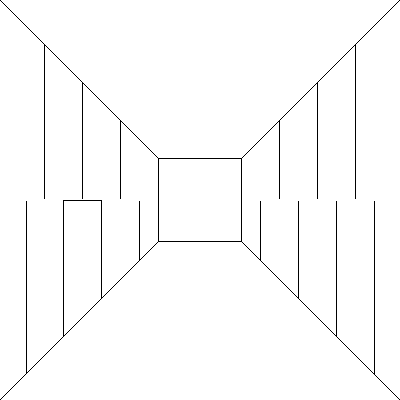
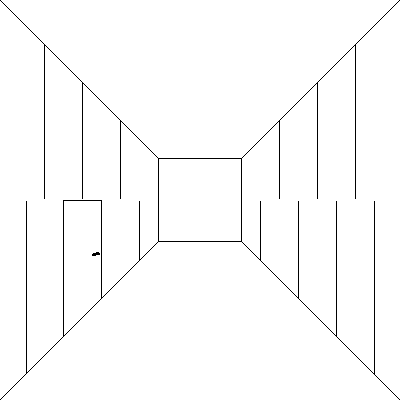
A jeśli dołożymy malutki szczegół?
Wróćmy jednak do wcześniejszej wersji
i lekko ją zmodyfikujmy - czy teraz potrafimy powiedzieć coś o orientacji?
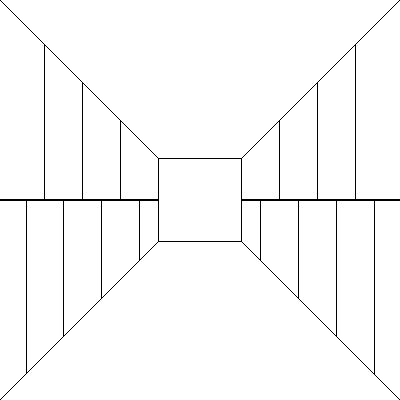
Mimo, iż mamy znacznie bogatszy obraz niż na samym początku (pusty korytarz) to nie jesteśmy w stanie powiedzieć nic więcej. Zatem ponownie dodajmy szczegół
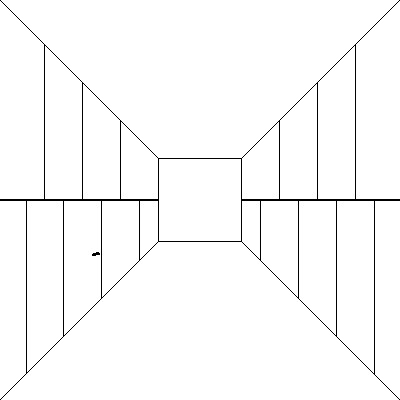
Można powiedzieć, iż obecność szczegółu w zupełności wystarczy do zorientowania obrazu i gdyby był bardziej widoczny to wystarczył by sam w sobie. Wracając do
porównajmy go z obróconą wersją
Ponownie pytamy: gdzie jest góra a gdzie dół?
Zapewne nie potrafimy odpowiedzieć. Zróbmy test i przyjrzyjmy się zatem kolejnym przykładom
Warunek: informacja musi dotyczyć obiektu który znamy, wiemy jak się zachowa (biorąc pod uwagę właściwości fizyczne).
Okazuje się jednak, że lokalność wcale nie jest wystarczająca. Przyjrzyjmy się następującym obrazom traktując je jako zupełnie niezależne



Każdy z tych obrazów lokalnie (traktowany niezależnie) jest poprawny i ma sens. Zestawione jednak razem budzą w nas pewien niepokój

a kompletny obraz zdecydowanie kłóci się z naszym postrzeganiem rzeczywistości.

Zapewne powiemy: to bez sensu, coś takiego nie może istnieć!
Uwaga! Nie oznacza to, że nie jest możliwe aby coś takiego istniało w rzeczywistości - nie istnieje tylko w naszej rzeczywistości i przez to odrzucamy to. Inaczej mówiąc, jest to sprzeczne z naszym doświadczeniem (wiedzą) dotyczącą otaczającego nas świata. W świecie, w którym żyjemy, coś takiego nie ma sensu.
Ale obiekty o takiej strukturze przestrzennej istnieją i są wykorzystywane przez człowieka!!!
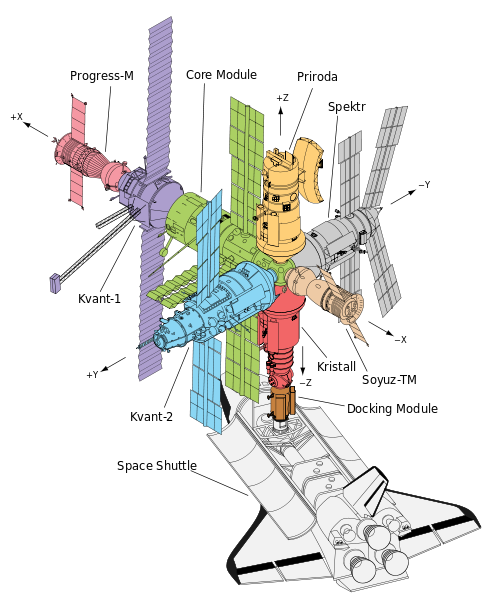
Problem w tym, że robot żyje w świecie jaki my jemu stworzymy. Kreując jego świat, niejako określamy to co może zobaczyć. W tym kontekście, z widzeniem jest tak samo jak z mową i językiem
Cóż to jednak jest kluczowy element? Co stanowi zbiór kluczowych elementów na przykład dla obiektu samochód? Czy koła? (wóz też ma koła) A szyby? (kabriolet nie ma szyb) A w ogóle to skąd wiemy, że w oknie są szyby? Zwykle ich nie widać. Spodziewamy się jednak, domyślamy się, zakładamy wręcz że tam są... gdyż ZWYKLE są.
Parafrazujące wcześniej przytoczone słowa
Dla porządku przypomnijmy: robot nie zna niczego.
Potwierdzeniem tego wniosku jest bardzo prosty test

A w tym przypadku?
Co widzimy na obrazku?

Zapewne starszą kobietę, gdyż w naszej rzeczywistości nie rozważamy nawet możliwości orentowania postaci ludzkiej ,,do góry nogami'' - przeszukując wzorce w naszej głowie, nie rozważamy takiej możliwości a więc i nie próbujemy nawet dokonać takiego dopasowania.

Kolejny przykład

Zapewne starszą kobietę.
O klasyfikacji obrazu decydują szczegóły, ale co najgorsze, każda z tych interpretacji jest poprawna. W tym przypadku istotny jest jeden szczegół - nos/profil twarzy. W życiu codziennym opisując twarz, rzadko opisujemy wygląd jej profilu, rzadko przyglądamy się profilom ludzi - zwykle patrzymy na nich na wprost. To uwarunkowanie sprawia, że mamy trudność w dostrzeżeniu młodej kobiety na tym rysunku (a właściwie to skąd pomysł, że ona jest młoda?!). W przypadku robotów też tak jest - one często widzą coś czego my nie wzięliśmy pod uwagę, co jednak jest jak najbardziej dopuszczalną interpretacja. Zasadniczy problem polega na tym jak ,,powiedzieć'' robotowi co i jak ma interpretować. Co by należało założyć w tym przykładzie?
Skoro mówimy już o pewnych (niejawnych) założeniach to spójrzmy na kolejny rysunek
Ile krzywych tutaj widać?
W wielu przypadkach trudno mówić jednak o elementach kluczowych

Często jednak nawet gdy one są to zestawione razem dają zupełnie inny obraz (poszczególne elementy, stanowiące dobrze zdefiniowane obiekty, połączone w jedną całość nabierają zupełnie innego znaczenia)


Zdolność człowieka do ,,widzenia'' wynika z ,,nawyków''. Problem w tym, że komputery i roboty nawyków nie mają. Im trzeba podać precyzyjny opis. Tyle tylko, że my ludzie sami mamy problem z odpowiedzeniem na pytanie o istotę mechanizmów widzenia, więc jak niby mamy skonstruować algorytm który by te procesy realizował?
Część III: co jeśli algorytmów nie potrafimy ułożyć?
A może nie konstruować algorytmów, tylko użyć technik, które przypominają w pewnym sensie to co się dzieje w naszej głowie?
Oto nasz obecny problem








Pytanie jest proste (odpowiedź nie): w jaki sposób ,,wydobyć'' z obrazu korytarz a konkretnie jego powierzchnię stanowiącą podłogę?
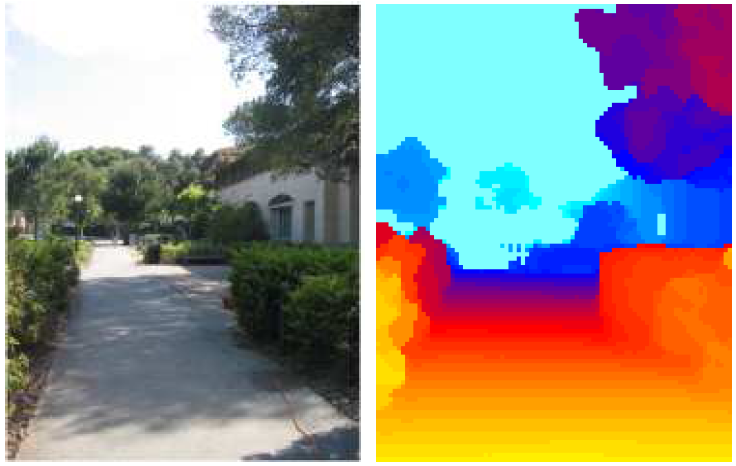
Może widzenie stereoskopowe?
Syntetyczne testy są bardzo obiecujące


I otrzymana mapa odległości
Po co to?
Idea.

Powód: zbyt monotonna kolorystyka pozbawiona istotnych szczegółów (porównaj z syntetycznym przykładem).
Może sztuczna sieć neuronowa?
Sztuczna sieć neuronowa i jej wykorzystanie do znajdywania podobnych fragmentów (obserwujmy jak sieć uczy się rozróżniać co raz większą liczbę szczegółów).










i test


Możemy naukę sieci kontynuować dalej










i test


Tak więc sieć może całkiem dobrze wyszukać podobne fragmenty. Jeśli teraz te fragmenty utworzą spójne obszary (na przykład obszar pokrywający podłogę) to takie podejście może być dla nas przydatne. Sprawdźmy to (w trzeciej kolumnie ,,kafelki'' z wzorcem widoczne na powiększeniu zostały zastąpione kafelkami jednokolorowymi; czwarta kolumna to obszary zidentyfikowane jako podłoga)













i test


Oraz kilka nowych obrazów testowych







Niestety także i teraz potwierdziło się, że na zdjęciach korytarza jest zbyt monotonna kolorystyka i są one pozbawione istotnych szczegółów.
Zauważmy, że w tym konkretnym przypadku dobre efekty daje zastosowanie najprostszego podejścia opartego na wykrywaniu krawędzi

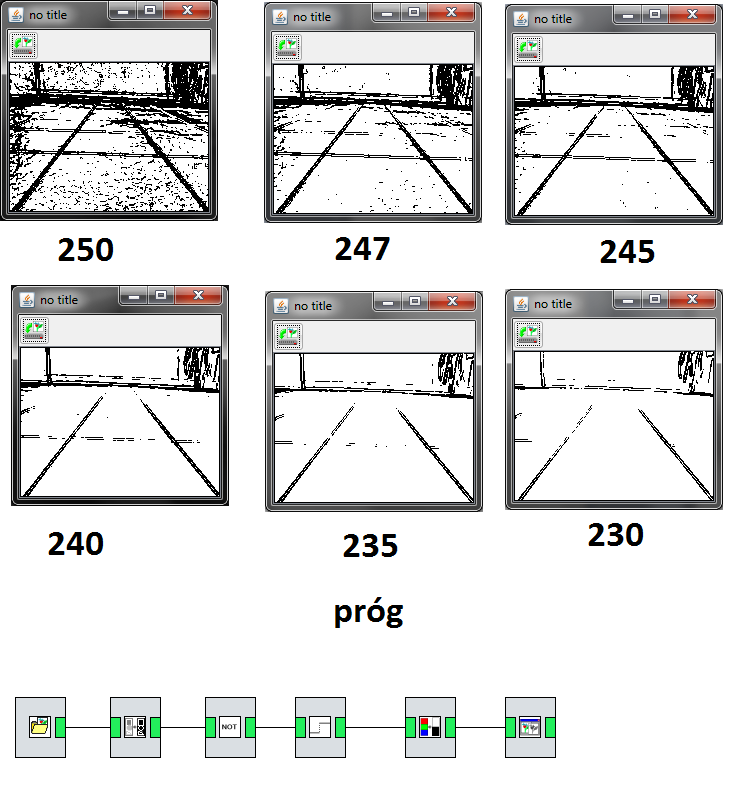
i gdyby chodziło o zbudowanie robota, który porusza się TYLKO po korytarzach naszego wydziału, to zapewne już dawno byśmy to zrobili.
Część IV: podsumowanie czyli ile pracy nas jeszcze czeka zanim roboty będą widziały.
Podsumowując możemy stwierdzić, że aby poprawnie interpretować obrazy należy użyć całego spektrum różnorodnych informacji. Ludzie wykorzystują wiele sygnałów (wskazówek) aby określić odległość czy lokalizować konkretne obiekty. Zasadniczo można je podzielić na trzy grupy: monocular, stereo, względność ruchu. Dopiero połączenie ich wszystkich ze sobą pozwala nam zrozumieć przestrzenną strukturę otaczającego nas świata.
Do wskazówek pochodzących z obrazów płaskich z pewnością zaliczyć możemy:
- tekstury i ich wariacje,
- gradienty i ich wariacje,
- występowanie znanych obiektów o znanych cechach i właściwościach,
- oświetlenie,
- cienie.
Zwykle obraz stereo nie jest przydatny jeśli rozpatrujemy odległe obiekty.
W ocenie odległości do obiektu może pomóc też względność ruchy, która wyraża się w tym, że obiekty bliższe wydają się poruszać szybciej od obiektów dalszych, poruszających się w rzeczywistości z tą samą prędkością.
Jeśli chcemy aby robot widział, wszystkie te czynniki musimy wziąć pod uwagę. Dopiero wielopłaszczyznowa analiza na poziomie lokalnym i globalnym pozwala faktycznie widzieć.