
- Before we start
- Install what you need
- Getting data
- Create relational database and import data into it
- Start Hadoop
- Prepare user account
- Import to HDFS
- Getting data back from HDFS
Note that in this tutorial
hadoop is a root Hadoop user while nosql is a typical, unprivilliged, user. I will write one of the following if the user is important:
|
1 |
nosql@nosql-vm:~$ |
or
|
1 |
hadoop@nosql-vm:~$ |
In other cases I will simply write:
|
1 |
$ |
For this part you need to have installed:
- Java
- Hadoop
- Sqoop
- PostgrSQL
To install all required components, please follow related documentation or you can check how I did it:
The easiest way to instal Java and PostgreSQL is to do this with pacgage manager, like Synapic, or simply with command line (it concerns Linux systems).
Fireballs and bolides are astronomical terms for exceptionally bright meteors that are spectacular enough to to be seen over a very wide area (see Fireball and Bolide Data).
You can get data about fireballs using simple exposed API Fireball Data API
Create working directory
|
1 2 3 |
nosql@nosql:~/Pulpit/nosql2$ mkdir hadoop_hdfs nosql@nosql:~/Pulpit/nosql2$ cd hadoop_hdfs/ nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ |
Either using wget
|
1 |
nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ wget https://ssd-api.jpl.nasa.gov/fireball.api?limit=20 -O fireball_data.json |
or with curl
|
1 |
nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ curl https://ssd-api.jpl.nasa.gov/fireball.api?limit=20 -o fireball_data.json |
Result
|
1 2 |
nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ cat fireball_data.json {"signature":{"source":"NASA/JPL Fireball Data API","version":"1.0"},"count":"20","fields":["date","energy","impact-e","lat","lat-dir","lon","lon-dir","alt","vel"],"data":[["2021-11-17 15:53:21","2.4","0.086","6.8","S","119.1","E","35.0","23.0"],["2021-11-08 05:28:28","3.3","0.11","33.8","S","7.7","W","36",null],["2021-10-28 09:10:30","3.0","0.1","4.1","S","138.7","W","35.2",null],["2021-10-21 10:32:02","3.7","0.13","51.5","N","51.4","E","30","15.9"],["2021-10-20 08:41:50","6.0","0.19","13.8","N","140.4","W","28",null],["2021-10-20 00:43:57","2.0","0.073","59.0","N","154.3","E","31.4","27.5"],["2021-09-29 10:50:59","13.7","0.4","53.9","N","148.0","W","28.0","21.2"],["2021-09-06 17:55:42","3.1","0.11","2.1","S","111.8","W","26.0","13.6"],["2021-07-30 08:06:34","14.6","0.42","7.8","S","90.1","E","63.0",null],["2021-07-29 13:19:57","3.7","0.13","42.4","N","98.4","E","26.4","14.7"],["2021-07-07 13:41:14","3.3","0.11",null,null,null,null,null,null],["2021-07-05 03:46:24","74","1.8","44.3","N","164.2","W","43.4","15.7"],["2021-06-09 05:43:59","2.3","0.082","17.9","S","55.3","W",null,null],["2021-05-16 15:51:08","3.8","0.13","52.1","S","171.2","W","37.0",null],["2021-05-06 05:54:27","2.1","0.076","34.7","S","141.0","E","31.0","26.6"],["2021-05-02 14:12:49","2.5","0.089","12.3","N","43.4","W",null,null],["2021-04-13 02:16:47","2.1","0.076","26.8","N","79.1","W","44.4","14.1"],["2021-04-02 15:52:58","13.7","0.4","71.2","N","106.7","E","40.0",null],["2021-03-06 08:43:06","14.1","0.41","48.6","S","90.4","E","31.1",null],["2021-03-05 13:50:01","3.9","0.13","81.1","S","141.1","E","32.5",null]]} |
Now we will use a few command line commands to extract important data from this JSON and save them in CSV file (turn off highlighting and use plain text mode below to see it correctly):
|
1 |
sed -e 's/":/"\n:/g' < fireball_data.json | sed -e '1,5d' -e 's/,"data"//' -e 's/\],\[/\n/g' -e 's/:\[//g' -e 's/\]\]}//g' -e 's/[][]//g' -e 's/"//g' |
Notice that part:
|
1 |
-e 's/[][]//g |
replaced more complex (turn off highlighting and use plain text mode below to see it correctly):
|
1 |
-e 's/\[\|\]//g' |
We can put part of this long command into a file json2csv to use multiple times easier:
|
1 2 3 4 5 6 7 8 |
#!/usr/bin/sed -f 1,5d s/,"data"// s/\],\[/\n/g s/:\[//g s/\]\]}//g s/[][]//g s/"//g' |
Set correct permissions so you could execute this file:
|
1 2 3 4 5 6 7 8 9 |
nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ ls -l razem 8 -rw-rw-r-- 1 nosql nosql 1609 lis 25 21:47 fireball_data.json -rw-rw-r-- 1 nosql nosql 82 lis 25 21:53 json2csv nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ chmod 764 json2csv nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ ls -l razem 8 -rw-rw-r-- 1 nosql nosql 1609 lis 25 21:47 fireball_data.json -rwxrw-r-- 1 nosql nosql 82 lis 25 21:53 json2csv |
Now we can call it as
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
$ sed -e 's/":/"\n:/g' < fireball_data.json | ./json2csv date,energy,impact-e,lat,lat-dir,lon,lon-dir,alt,vel 2021-11-17 15:53:21,2.4,0.086,6.8,S,119.1,E,35.0,23.0 2021-11-08 05:28:28,3.3,0.11,33.8,S,7.7,W,36,null 2021-10-28 09:10:30,3.0,0.1,4.1,S,138.7,W,35.2,null 2021-10-21 10:32:02,3.7,0.13,51.5,N,51.4,E,30,15.9 2021-10-20 08:41:50,6.0,0.19,13.8,N,140.4,W,28,null 2021-10-20 00:43:57,2.0,0.073,59.0,N,154.3,E,31.4,27.5 2021-09-29 10:50:59,13.7,0.4,53.9,N,148.0,W,28.0,21.2 2021-09-06 17:55:42,3.1,0.11,2.1,S,111.8,W,26.0,13.6 2021-07-30 08:06:34,14.6,0.42,7.8,S,90.1,E,63.0,null 2021-07-29 13:19:57,3.7,0.13,42.4,N,98.4,E,26.4,14.7 2021-07-07 13:41:14,3.3,0.11,null,null,null,null,null,null 2021-07-05 03:46:24,74,1.8,44.3,N,164.2,W,43.4,15.7 2021-06-09 05:43:59,2.3,0.082,17.9,S,55.3,W,null,null 2021-05-16 15:51:08,3.8,0.13,52.1,S,171.2,W,37.0,null 2021-05-06 05:54:27,2.1,0.076,34.7,S,141.0,E,31.0,26.6 2021-05-02 14:12:49,2.5,0.089,12.3,N,43.4,W,null,null 2021-04-13 02:16:47,2.1,0.076,26.8,N,79.1,W,44.4,14.1 2021-04-02 15:52:58,13.7,0.4,71.2,N,106.7,E,40.0,null 2021-03-06 08:43:06,14.1,0.41,48.6,S,90.4,E,31.1,null 2021-03-05 13:50:01,3.9,0.13,81.1,S,141.1,E,32.5,null |
As all tests are positive you can save result to fireball_data.csv file
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ sed -e 's/":/"\n:/g' < fireball_data.json | ./json2csv > fireball_data.csv nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ cat fireball_data.csv date,energy,impact-e,lat,lat-dir,lon,lon-dir,alt,vel 2021-11-17 15:53:21,2.4,0.086,6.8,S,119.1,E,35.0,23.0 2021-11-08 05:28:28,3.3,0.11,33.8,S,7.7,W,36,null 2021-10-28 09:10:30,3.0,0.1,4.1,S,138.7,W,35.2,null 2021-10-21 10:32:02,3.7,0.13,51.5,N,51.4,E,30,15.9 2021-10-20 08:41:50,6.0,0.19,13.8,N,140.4,W,28,null 2021-10-20 00:43:57,2.0,0.073,59.0,N,154.3,E,31.4,27.5 2021-09-29 10:50:59,13.7,0.4,53.9,N,148.0,W,28.0,21.2 2021-09-06 17:55:42,3.1,0.11,2.1,S,111.8,W,26.0,13.6 2021-07-30 08:06:34,14.6,0.42,7.8,S,90.1,E,63.0,null 2021-07-29 13:19:57,3.7,0.13,42.4,N,98.4,E,26.4,14.7 2021-07-07 13:41:14,3.3,0.11,null,null,null,null,null,null 2021-07-05 03:46:24,74,1.8,44.3,N,164.2,W,43.4,15.7 2021-06-09 05:43:59,2.3,0.082,17.9,S,55.3,W,null,null 2021-05-16 15:51:08,3.8,0.13,52.1,S,171.2,W,37.0,null 2021-05-06 05:54:27,2.1,0.076,34.7,S,141.0,E,31.0,26.6 2021-05-02 14:12:49,2.5,0.089,12.3,N,43.4,W,null,null 2021-04-13 02:16:47,2.1,0.076,26.8,N,79.1,W,44.4,14.1 2021-04-02 15:52:58,13.7,0.4,71.2,N,106.7,E,40.0,null 2021-03-06 08:43:06,14.1,0.41,48.6,S,90.4,E,31.1,null 2021-03-05 13:50:01,3.9,0.13,81.1,S,141.1,E,32.5,null |
Login to PostgreSQL. To do this, you have three options:
- best: add another one superuse without touching default postgres [1];
- change pasword of default postgres;
- add "normal" user.
Please read also the following materials:
- How to Install PostgreSQL and phpPgAdmin on Ubuntu 20.04 LTS
- How to install PostgreSQL and phpPgAdmin
- What's the default superuser username/password for postgres after a new install?
I select the first option, and I'm going to add another one superuse without touching default postgres superuser.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ sudo -i -u postgres psql [sudo] password for noslq: psql (13.5 (Ubuntu 13.5-0ubuntu0.21.10.1)) Type "help" for help. postgres=# CREATE ROLE pgsuperuser WITH SUPERUSER CREATEDB CREATEROLE LOGIN ENCRYPTED PASSWORD 'pgsuperuserpass'; CREATE ROLE postgres=# \du List of roles Role name | Attributes | Member of -------------+------------------------------------------------------------+----------- pgsuperuser | Superuser, Create role, Create DB | {} postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {} postgres=# \q |
Now it is possible to use phpPgAdmin at 127.0.0.1/phppgadmin:
|
|
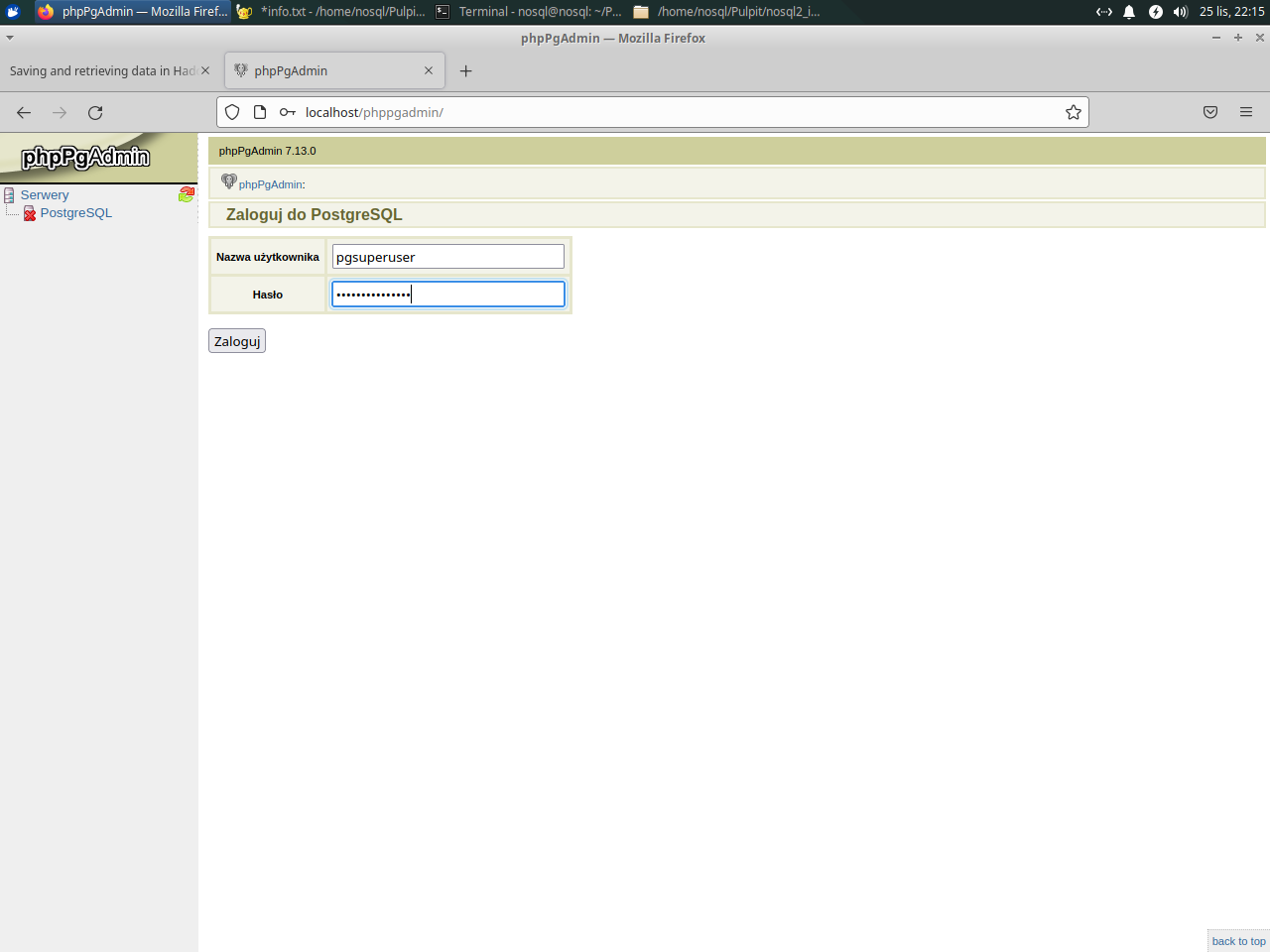
|

|
Create database nosql
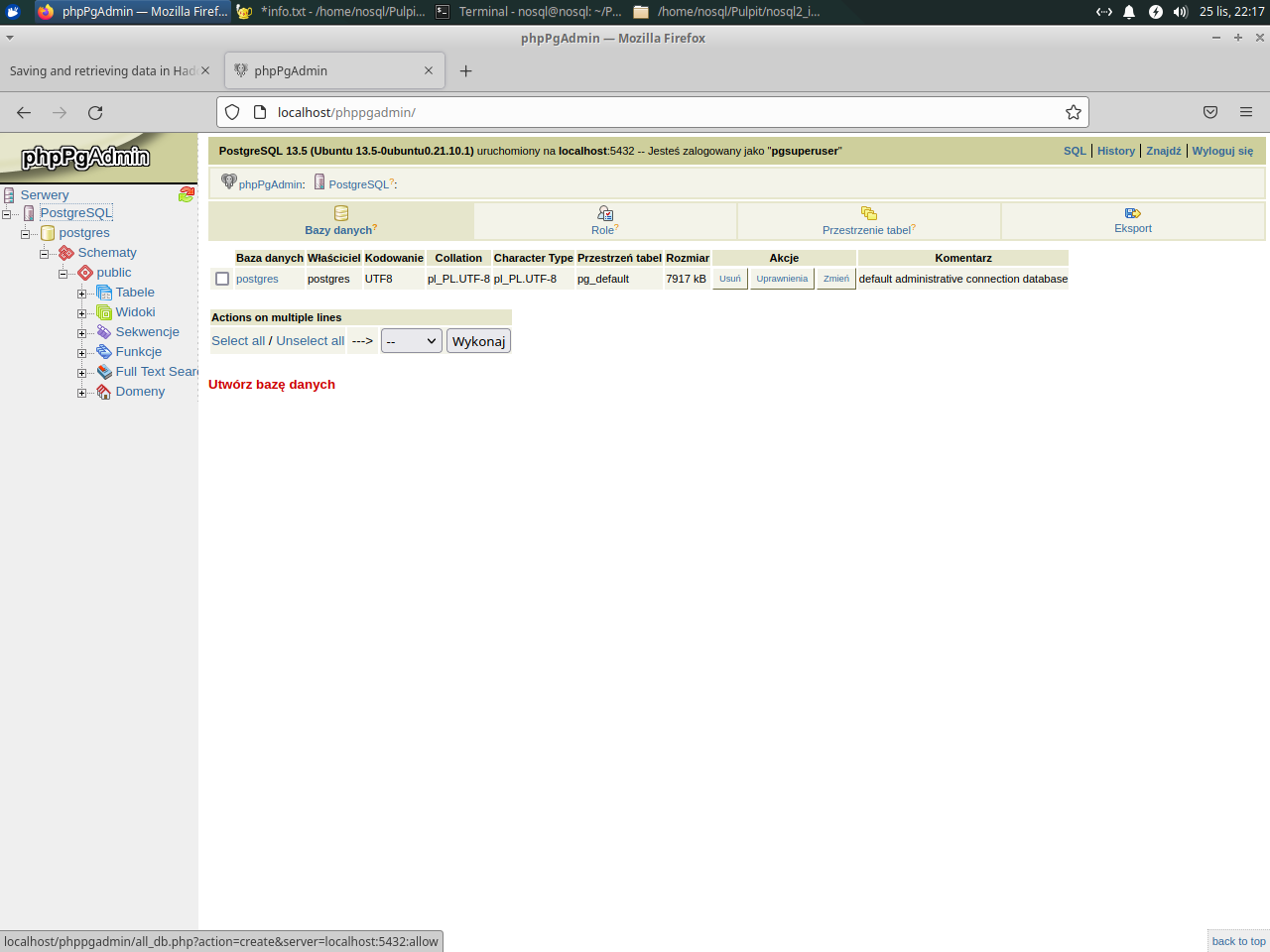
|

|
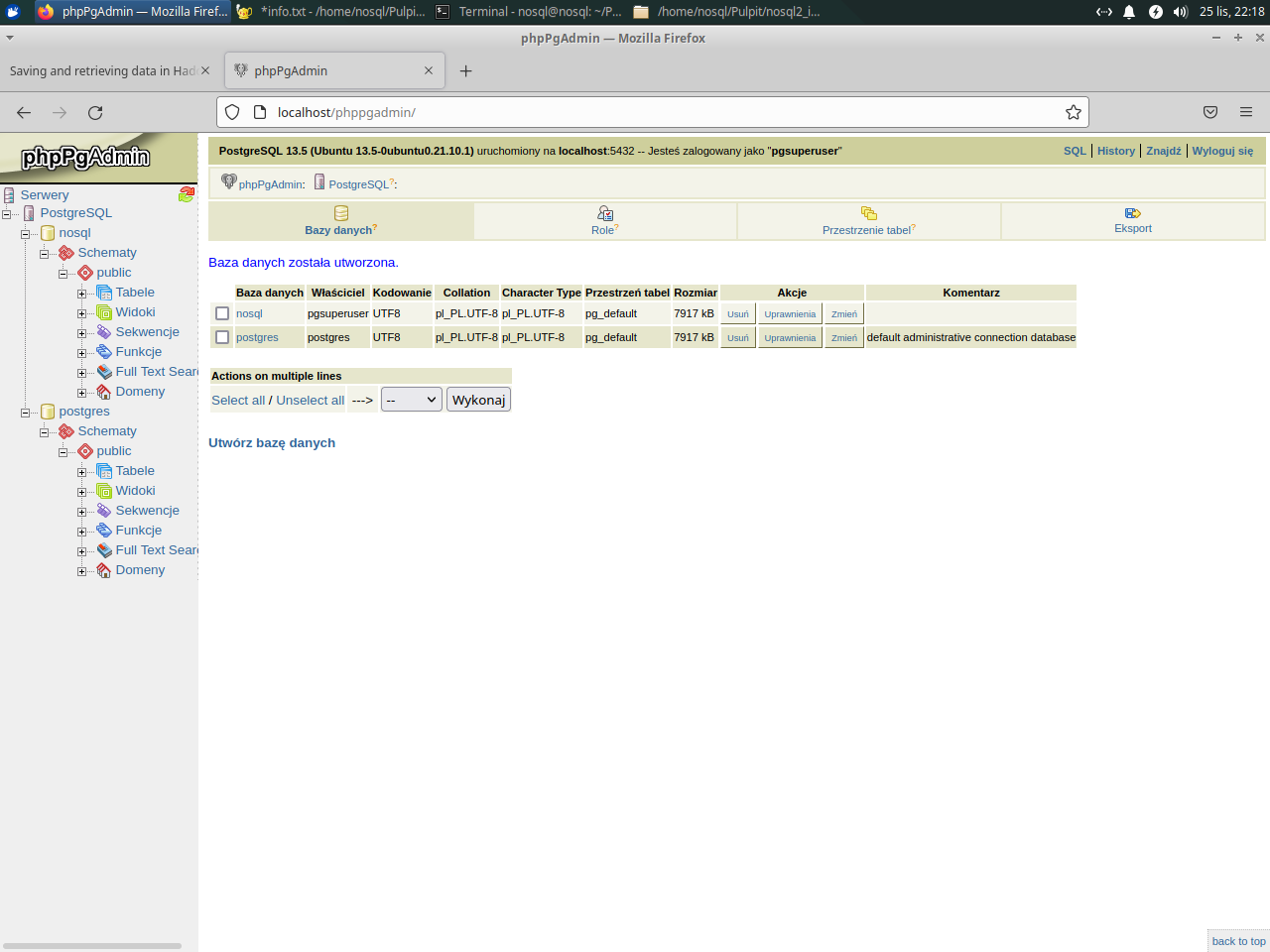
|
Create table

|

|
Put this code in SQL textarea:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE TYPE lat_dir as enum('N', 'S'); CREATE TYPE lon_dir as enum('E', 'W'); CREATE TABLE fireball ( id SERIAL PRIMARY KEY, date DATE, energy REAL, impact_e REAL, lat REAL, lat_dir lat_dir, lon REAL, lon_dir lon_dir, alt REAL, vel REAL ); |

|

|

|

|
Import a CSV file into a table using COPY statement
|
1 2 3 4 5 6 |
COPY fireball (date, energy, impact_e, lat, lat_dir, lon, lon_dir, alt, vel) FROM '/home/nosql/Pulpit/nosql2/hadoop_hdfs/fireball_data.csv' WITH DELIMITER ',' NULL AS 'null' CSV HEADER; |
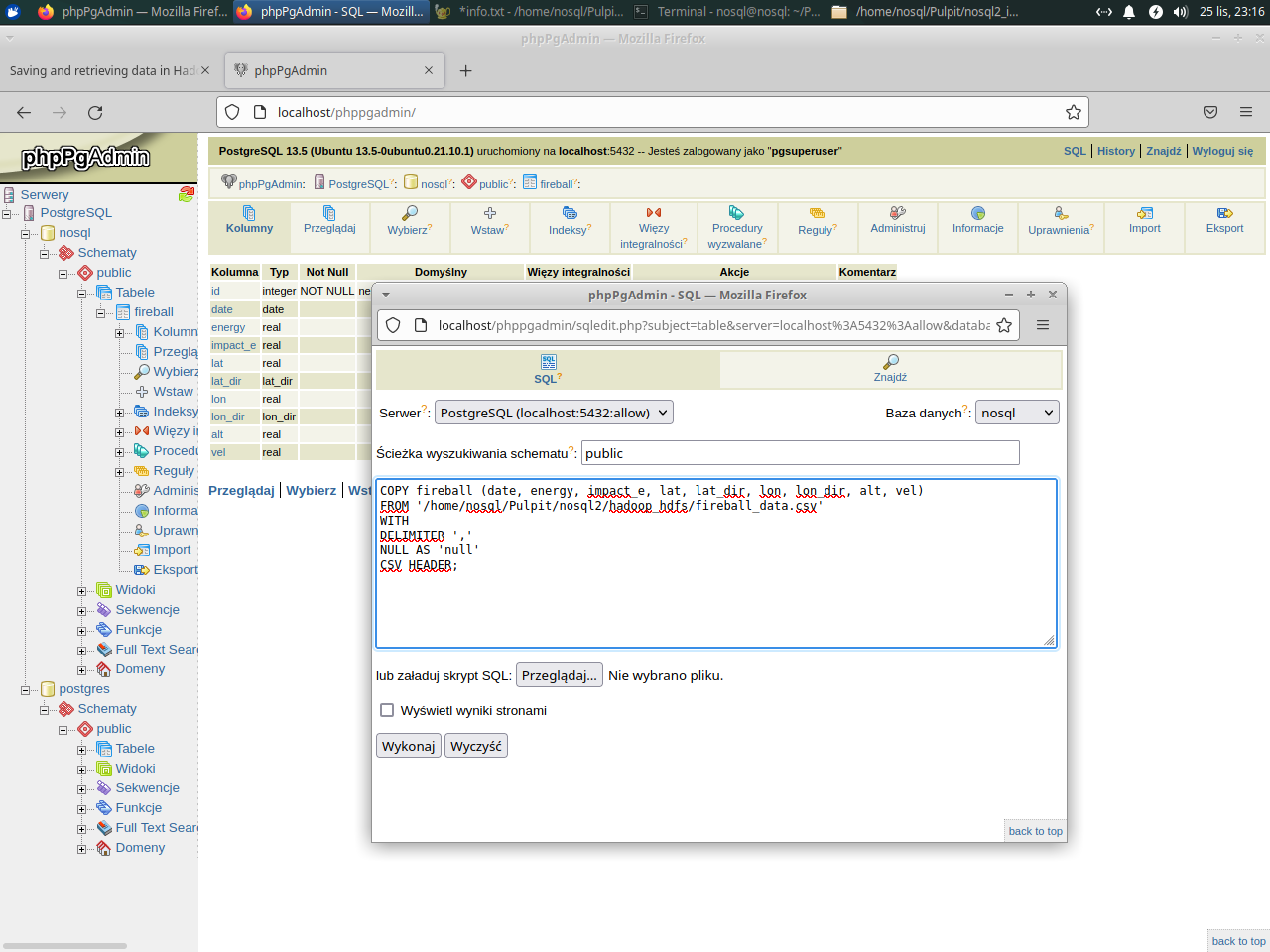
|

|
In case of problem with reading:
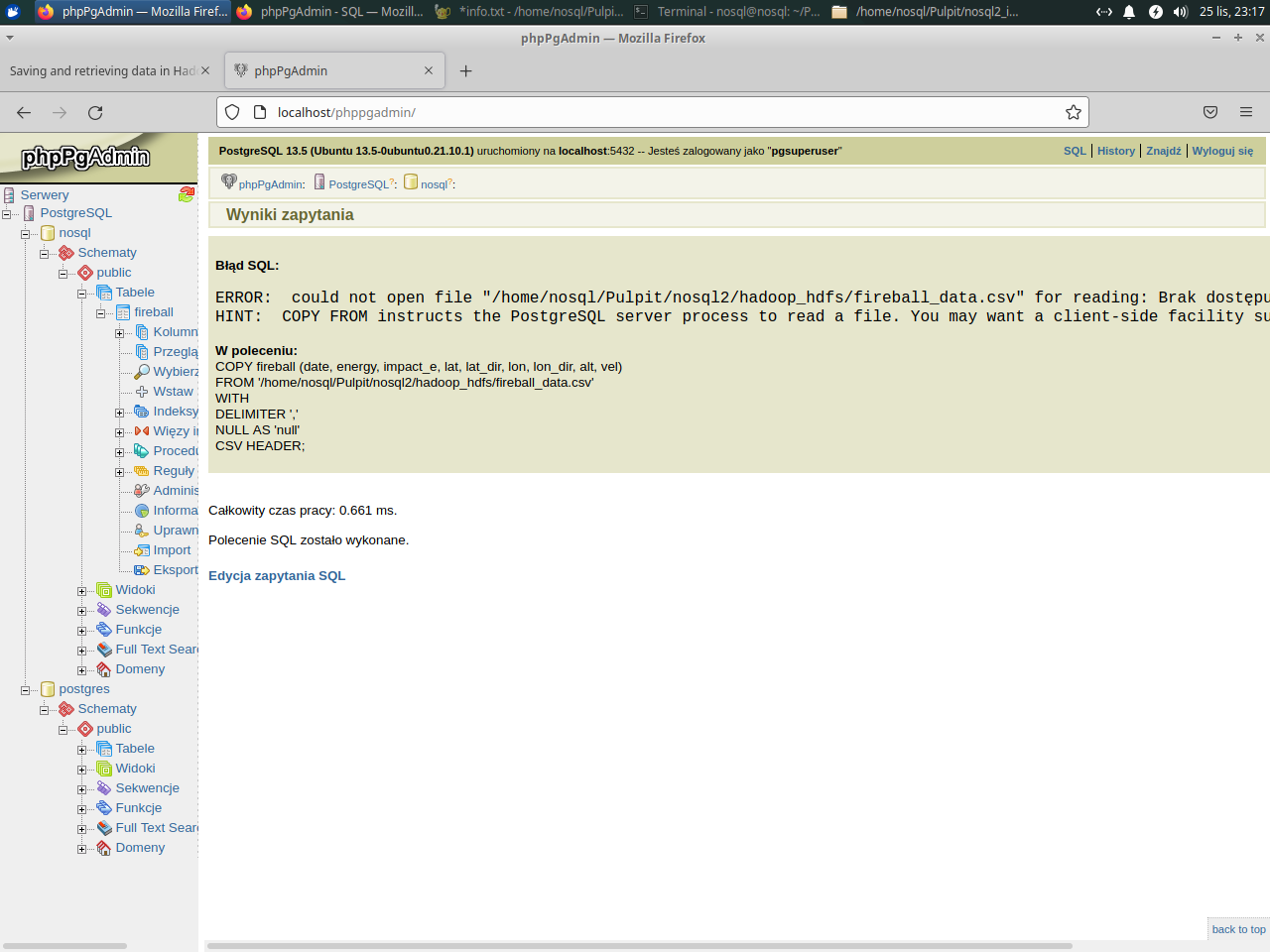
|

|
Please verify all right to directories and files. For example:
|
1 2 3 4 5 6 7 8 9 10 |
nosql@nosql:~/Pulpit/nosql2$ cd /home/ nosql@nosql:/home$ ls -l razem 8 drwxr-x--- 6 hadoop hadoop 4096 lis 25 14:07 hadoop drwxr-x--- 17 nosql nosql 4096 lis 25 21:42 nosql nosql@nosql:/home$ chmod o+x nosql/ nosql@nosql:/home$ ls -l razem 8 drwxr-x--- 6 hadoop hadoop 4096 lis 25 14:07 hadoop drwxr-x--x 17 nosql nosql 4096 lis 25 21:42 nosql |

|

|
Export data from a table to CSV using COPY statement
|
1 2 3 4 5 6 |
COPY fireball (date, energy, impact_e, lat, lat_dir, lon, lon_dir, alt, vel) TO '/home/nosql/Pulpit/nosql2/hadoop_hdfs/fireball_data_from_postgresql.csv' WITH DELIMITER ',' NULL AS 'null' CSV HEADER; |

|
In case of problem with saving

|

|
create an empty file manually and set correct permissions:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ ls -l razem 12 -rw-rw-r-- 1 nosql nosql 1124 lis 25 22:04 fireball_data.csv -rw-rw-r-- 1 nosql nosql 1609 lis 25 21:47 fireball_data.json -rwxrw-r-- 1 nosql nosql 82 lis 25 21:53 json2csv nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ touch fireball_data_from_postgresql.csv nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ ls -l razem 12 -rw-rw-r-- 1 nosql nosql 1124 lis 25 22:04 fireball_data.csv -rw-rw-r-- 1 nosql nosql 0 lis 25 23:33 fireball_data_from_postgresql.csv -rw-rw-r-- 1 nosql nosql 1609 lis 25 21:47 fireball_data.json -rwxrw-r-- 1 nosql nosql 82 lis 25 21:53 json2csv nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ chmod 666 fireball_data_from_postgresql.csv nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ ls -l razem 12 -rw-rw-r-- 1 nosql nosql 1124 lis 25 22:04 fireball_data.csv -rw-rw-rw- 1 nosql nosql 0 lis 25 23:33 fireball_data_from_postgresql.csv -rw-rw-r-- 1 nosql nosql 1609 lis 25 21:47 fireball_data.json -rwxrw-r-- 1 nosql nosql 82 lis 25 21:53 json2csv |

|
Compare exported version (fireball_data_from_postgresql.csv) file:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ ls -l razem 16 -rw-rw-r-- 1 nosql nosql 1124 lis 25 22:04 fireball_data.csv -rw-rw-rw- 1 nosql nosql 916 lis 25 23:35 fireball_data_from_postgresql.csv -rw-rw-r-- 1 nosql nosql 1609 lis 25 21:47 fireball_data.json -rwxrw-r-- 1 nosql nosql 82 lis 25 21:53 json2csv nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ cat fireball_data_from_postgresql.csv date,energy,impact_e,lat,lat_dir,lon,lon_dir,alt,vel 2021-11-17,2.4,0.086,6.8,S,119.1,E,35,23 2021-11-08,3.3,0.11,33.8,S,7.7,W,36,null 2021-10-28,3,0.1,4.1,S,138.7,W,35.2,null 2021-10-21,3.7,0.13,51.5,N,51.4,E,30,15.9 2021-10-20,6,0.19,13.8,N,140.4,W,28,null 2021-10-20,2,0.073,59,N,154.3,E,31.4,27.5 2021-09-29,13.7,0.4,53.9,N,148,W,28,21.2 2021-09-06,3.1,0.11,2.1,S,111.8,W,26,13.6 2021-07-30,14.6,0.42,7.8,S,90.1,E,63,null 2021-07-29,3.7,0.13,42.4,N,98.4,E,26.4,14.7 2021-07-07,3.3,0.11,null,null,null,null,null,null 2021-07-05,74,1.8,44.3,N,164.2,W,43.4,15.7 2021-06-09,2.3,0.082,17.9,S,55.3,W,null,null 2021-05-16,3.8,0.13,52.1,S,171.2,W,37,null 2021-05-06,2.1,0.076,34.7,S,141,E,31,26.6 2021-05-02,2.5,0.089,12.3,N,43.4,W,null,null 2021-04-13,2.1,0.076,26.8,N,79.1,W,44.4,14.1 2021-04-02,13.7,0.4,71.2,N,106.7,E,40,null 2021-03-06,14.1,0.41,48.6,S,90.4,E,31.1,null 2021-03-05,3.9,0.13,81.1,S,141.1,E,32.5,null |
with original (fireball_data.csv) file:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ cat fireball_data.csv date,energy,impact-e,lat,lat-dir,lon,lon-dir,alt,vel 2021-11-17 15:53:21,2.4,0.086,6.8,S,119.1,E,35.0,23.0 2021-11-08 05:28:28,3.3,0.11,33.8,S,7.7,W,36,null 2021-10-28 09:10:30,3.0,0.1,4.1,S,138.7,W,35.2,null 2021-10-21 10:32:02,3.7,0.13,51.5,N,51.4,E,30,15.9 2021-10-20 08:41:50,6.0,0.19,13.8,N,140.4,W,28,null 2021-10-20 00:43:57,2.0,0.073,59.0,N,154.3,E,31.4,27.5 2021-09-29 10:50:59,13.7,0.4,53.9,N,148.0,W,28.0,21.2 2021-09-06 17:55:42,3.1,0.11,2.1,S,111.8,W,26.0,13.6 2021-07-30 08:06:34,14.6,0.42,7.8,S,90.1,E,63.0,null 2021-07-29 13:19:57,3.7,0.13,42.4,N,98.4,E,26.4,14.7 2021-07-07 13:41:14,3.3,0.11,null,null,null,null,null,null 2021-07-05 03:46:24,74,1.8,44.3,N,164.2,W,43.4,15.7 2021-06-09 05:43:59,2.3,0.082,17.9,S,55.3,W,null,null 2021-05-16 15:51:08,3.8,0.13,52.1,S,171.2,W,37.0,null 2021-05-06 05:54:27,2.1,0.076,34.7,S,141.0,E,31.0,26.6 2021-05-02 14:12:49,2.5,0.089,12.3,N,43.4,W,null,null 2021-04-13 02:16:47,2.1,0.076,26.8,N,79.1,W,44.4,14.1 2021-04-02 15:52:58,13.7,0.4,71.2,N,106.7,E,40.0,null 2021-03-06 08:43:06,14.1,0.41,48.6,S,90.4,E,31.1,null 2021-03-05 13:50:01,3.9,0.13,81.1,S,141.1,E,32.5,null nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ |
You can also try to use command line for the above following this pattern (this is only an example - you have to adjust it to our example)
|
1 |
cat output.json | psql -h localhost -p 5432 postgres -U postgres -c "COPY temp (data) FROM STDIN;" |
If it's not running yet, start Hadoop. Do this as a Hadoop superuser (
hadoop in my case):
|
1 2 3 4 5 6 7 8 9 |
nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ su hadoop Hasło: hadoop@nosql:/home/nosql/Pulpit/nosql2/hadoop_hdfs$ start-dfs.sh Starting namenodes on [localhost] Starting datanodes Starting secondary namenodes [nosql] hadoop@nosql:/home/nosql/Pulpit/nosql2/hadoop_hdfs$ start-yarn.sh Starting resourcemanager Starting nodemanagers |
Now we have to be sure that all necessary HDFS and Hadoop accounts for user exists. In order to enable new user to use your Hadoop cluster, follow these general steps.
- Create the group
1$ sudo groupadd hadoopuser - If user doesn't exist
Create an OS account on the Linux system from which you want to let a user execute Hadoop jobs.
12$ sudo useradd –g hadoopuser newuser$ sudo passwd newuser
Note:-gThe group name or number of the user's initial login group.-GA list of supplementary groups which the user is also a member of.
According to my test option
-gshould be used to pass Hadoop user verification process. - If user exists
Create an OS account on the Linux system from which you want to let a user execute Hadoop jobs.12345nosql@nosql:~$ groupsnosql adm cdrom sudo dip plugdev lpadmin lxd sambasharenosql@nosql:~$ iduid=1000(nosql) gid=1000(nosql) grupy=1000(nosql),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),123(lpadmin),132(lxd),133(sambashare)nosql@nosql:~$ sudo usermod -g hadoopuser nosqlNote:
-aappend group to existing user's groups. Without this new group will overwrite all existing groups when-Gis used.
- To make new gropu membership active you have to relogin (logout and then login):
1234nosql@nosql:~$ groupshadoopuser adm cdrom sudo dip plugdev lpadmin lxd sambasharenosql@nosql:~$ iduid=1000(nosql) gid=1002(hadoopuser) grupy=1002(hadoopuser),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),123(lpadmin),132(lxd),133(sambashare)
- In order to create a new HDFS user, you need to create a directory under the
/userdirectory. This directory will serve as the HDFS home directory for the user.
12345678hadoop@nosql:/home/nosql$ hdfs dfs -ls /Found 1 itemsdrwxr-xr-x - hadoop supergroup 0 2021-11-25 14:34 /testhadoop@nosql:/home/nosql$ hdfs dfs -mkdir /userhadoop@nosql:/home/nosql$ hdfs dfs -mkdir /user/nosqlhadoop@nosql:/home/nosql$ hdfs dfs -ls /userFound 1 itemsdrwxr-xr-x - hadoop supergroup 0 2021-11-25 23:58 /user/nosql - Change the ownership of the directory, since you don’t want to use the default owner/group (
hadoop/supergroup) for this directory.
1234567hadoop@nosql:/home/nosql$ hdfs dfs -ls /userFound 1 itemsdrwxr-xr-x - hadoop supergroup 0 2021-11-25 23:58 /user/nosqlhadoop@nosql:/home/nosql$ hdfs dfs -chown nosql:hadoopuser /user/nosqlhadoop@nosql:/home/nosql$ hdfs dfs -ls /userFound 1 itemsdrwxr-xr-x - nosql hadoopuser 0 2021-11-25 23:58 /user/nosql
Usernosqlcan now store the output of his/her MapReduce and other jobs under that user’s home directory in HDFS. -
Refresh the user and group mappings to let the NameNode know about the new user:
12hadoop@nosql:/home/nosql$ hdfs dfsadmin -refreshUserToGroupsMappingsRefresh user to groups mapping successful - Make sure that all the permissions on the Hadoop temp directory (which is specified in the
core-site.xmlfile) are so all Hadoop users can access. Default temp directory is defined as below:
1234<property><name>hadoop.tmp.dir</name><value>/tmp/hadoop-$(user.name)</value></property>- Check existing ownership
12345678910hadoop@nosql:/home/nosql$ hdfs dfs -ls /Found 2 itemsdrwxr-xr-x - hadoop supergroup 0 2021-11-25 14:34 /testdrwxr-xr-x - hadoop supergroup 0 2021-11-25 23:58 /userhadoop@nosql:/home/nosql$ hdfs dfs -mkdir /tmphadoop@nosql:/home/nosql$ hdfs dfs -ls /Found 3 itemsdrwxr-xr-x - hadoop supergroup 0 2021-11-25 14:34 /testdrwxr-xr-x - hadoop supergroup 0 2021-11-26 00:07 /tmpdrwxr-xr-x - hadoop supergroup 0 2021-11-25 23:58 /user - Create temp directory for
nosqluser
1234hadoop@nosql:/home/nosql$ hdfs dfs -mkdir /tmp/hadoop-nosqlhadoop@nosql:/home/nosql$ hdfs dfs -ls /tmpFound 1 itemsdrwxr-xr-x - hadoop supergroup 0 2021-11-26 00:08 /tmp/hadoop-nosql - Change ownership of newly created directory (owner to
nosqland group tohadoopuser)
12345678hadoop@nosql:/home/nosql$ hdfs dfs -chown nosql /tmp/hadoop-nosqlhadoop@nosql:/home/nosql$ hdfs dfs -ls /tmpFound 1 itemsdrwxr-xr-x - nosql supergroup 0 2021-11-26 00:08 /tmp/hadoop-nosqlhadoop@nosql:/home/nosql$ hdfs dfs -chgrp -R hadoopuser /tmphadoop@nosql:/home/nosql$ hdfs dfs -ls /tmpFound 1 itemsdrwxr-xr-x - nosql hadoopuser 0 2021-11-26 00:08 /tmp/hadoop-nosql - Change right of
tmpdirectory
1234567891011hadoop@nosql:/home/nosql$ hdfs dfs -ls /Found 3 itemsdrwxr-xr-x - hadoop supergroup 0 2021-11-25 14:34 /testdrwxr-xr-x - hadoop hadoopuser 0 2021-11-26 00:08 /tmpdrwxr-xr-x - hadoop supergroup 0 2021-11-25 23:58 /userhadoop@nosql:/home/nosql$ hdfs dfs -chmod -R 770 /tmphadoop@nosql:/home/nosql$ hdfs dfs -ls /Found 3 itemsdrwxr-xr-x - hadoop supergroup 0 2021-11-25 14:34 /testdrwxrwx--- - hadoop hadoopuser 0 2021-11-26 00:08 /tmpdrwxr-xr-x - hadoop supergroup 0 2021-11-25 23:58 /user
- Check existing ownership
The new user can now log into the gateway servers and execute his or her Hadoop jobs and store data in HDFS.
- Put JDBC connector in correct dir (
/usr/lib/sqoop/libin my case; connectorpostgresql-42.2.18.jar). - Checking version
12345678910111213nosql@nosql:~$ sqoop versionWarning: /usr/lib/sqoop/../hbase does not exist! HBase imports will fail.Please set $HBASE_HOME to the root of your HBase installation.Warning: /usr/lib/sqoop/../hcatalog does not exist! HCatalog jobs will fail.Please set $HCAT_HOME to the root of your HCatalog installation.Warning: /usr/lib/sqoop/../accumulo does not exist! Accumulo imports will fail.Please set $ACCUMULO_HOME to the root of your Accumulo installation.Warning: /usr/lib/sqoop/../zookeeper does not exist! Accumulo imports will fail.Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.2021-11-26 00:13:44,680 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7Sqoop 1.4.7git commit id 2328971411f57f0cb683dfb79d19d4d19d185dd8Compiled by maugli on Thu Dec 21 15:59:58 STD 2017 - First try and first problem. Solving
java.lang.NoClassDefFoundError: org/apache/commons/lang/StringUtilsproblem
12345678910111213141516171819202122232425nosql@nosql:~$ sqoop import -connect 'jdbc:postgresql://127.0.0.1:5432/nosql' --username 'pgsuperuser' --password 'pgsuperuserpass' --table 'fireball' --target-dir 'fireball'Warning: /usr/lib/sqoop/../hbase does not exist! HBase imports will fail.Please set $HBASE_HOME to the root of your HBase installation.Warning: /usr/lib/sqoop/../hcatalog does not exist! HCatalog jobs will fail.Please set $HCAT_HOME to the root of your HCatalog installation.Warning: /usr/lib/sqoop/../accumulo does not exist! Accumulo imports will fail.Please set $ACCUMULO_HOME to the root of your Accumulo installation.Warning: /usr/lib/sqoop/../zookeeper does not exist! Accumulo imports will fail.Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.2021-11-26 00:15:35,105 INFO sqoop.Sqoop: Running Sqoop version: 1.4.72021-11-26 00:15:35,171 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/commons/lang/StringUtilsat org.apache.sqoop.tool.BaseSqoopTool.validateHiveOptions(BaseSqoopTool.java:1583)at org.apache.sqoop.tool.ImportTool.validateOptions(ImportTool.java:1178)at org.apache.sqoop.Sqoop.run(Sqoop.java:137)at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)at org.apache.sqoop.Sqoop.main(Sqoop.java:252)Caused by: java.lang.ClassNotFoundException: org.apache.commons.lang.StringUtilsat java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(BuiltinClassLoader.java:581)at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(ClassLoaders.java:178)at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:522)... 8 more
Locate all file havingcommons-langin their name:
123456789nosql@nosql:/home/nosql$ locate commons-langnosql@nosql:/home/nosql$ sudo updatedb[sudo] hasło użytkownika nosql:hadoop@nosql:/home/nosql$ locate commons-lang/home/nosql/Pulpit/nosql2/apache-tinkerpop-gremlin-console-3.5.1/lib/commons-lang3-3.11.jar/usr/lib/sqoop/lib/commons-lang3-3.4.jar/usr/local/hadoop/share/hadoop/common/lib/commons-lang3-3.7.jar/usr/local/hadoop/share/hadoop/hdfs/lib/commons-lang3-3.7.jar/usr/local/hadoop/share/hadoop/yarn/timelineservice/lib/commons-lang-2.6.jar
Move correct file to Sqoop folder:
1234nosql@nosql:~$ cp /usr/local/hadoop/share/hadoop/yarn/timelineservice/lib/commons-lang-2.6.jar /usr/lib/sqoop/lib/nosql@nosql:~$ ls -la /usr/lib/sqoop/lib/ | grep lang-rw-r--r-- 1 nosql hadoopuser 284220 lis 26 00:27 commons-lang-2.6.jar-rw-rw-r-- 1 nosql nosql 434678 gru 19 2017 commons-lang3-3.4.jar - Second try and second problem. This problem may be related with incorrect JDBC URL syntax. You need to ensure that the JDBC URL is conform the JDBC driver documentation and keep in mind that it's usually case sensitive (see The infamous java.sql.SQLException: No suitable driver found: 2. Or, JDBC URL is in wrong syntax).
- In case of PostgreSQL this takes one of the following forms:
123jdbc:postgresql:databasejdbc:postgresql://host/databasejdbc:postgresql://host:port/database - In case of MySQL this takes the following form:
1jdbc:mysql://[host1][:port1][,[host2][:port2]]...[/[database]] [?propertyName1=propertyValue1[&propertyName2=propertyValue2]...] - In case of Oracle there are 2 URL syntax, old syntax which will only work with SID and the new one with Oracle service name:
123Old syntax jdbc:oracle:thin:@[HOST][:PORT]:SIDNew syntax jdbc:oracle:thin:@//[HOST][:PORT]/SERVICE
- In case of PostgreSQL this takes one of the following forms:
- Success
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687nosql@nosql:~$ sqoop import -connect 'jdbc:postgresql://127.0.0.1:5432/nosql' --username 'pgsuperuser' --password 'pgsuperuserpass' --table 'fireball' --target-dir 'fireball'Warning: /usr/lib/sqoop/../hbase does not exist! HBase imports will fail.Please set $HBASE_HOME to the root of your HBase installation.Warning: /usr/lib/sqoop/../hcatalog does not exist! HCatalog jobs will fail.Please set $HCAT_HOME to the root of your HCatalog installation.Warning: /usr/lib/sqoop/../accumulo does not exist! Accumulo imports will fail.Please set $ACCUMULO_HOME to the root of your Accumulo installation.Warning: /usr/lib/sqoop/../zookeeper does not exist! Accumulo imports will fail.Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.2021-11-26 00:28:56,303 INFO sqoop.Sqoop: Running Sqoop version: 1.4.72021-11-26 00:28:56,379 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.2021-11-26 00:28:56,582 INFO manager.SqlManager: Using default fetchSize of 10002021-11-26 00:28:56,582 INFO tool.CodeGenTool: Beginning code generation2021-11-26 00:28:57,299 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM "fireball" AS t LIMIT 12021-11-26 00:28:57,377 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoopNote: /tmp/sqoop-nosql/compile/8437db96d955576560b5f3a1f84260c2/fireball.java uses or overrides a deprecated API.Note: Recompile with -Xlint:deprecation for details.2021-11-26 00:29:00,611 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-nosql/compile/8437db96d955576560b5f3a1f84260c2/fireball.jar2021-11-26 00:29:00,648 WARN manager.PostgresqlManager: It looks like you are importing from postgresql.2021-11-26 00:29:00,648 WARN manager.PostgresqlManager: This transfer can be faster! Use the --direct2021-11-26 00:29:00,648 WARN manager.PostgresqlManager: option to exercise a postgresql-specific fast path.2021-11-26 00:29:00,658 INFO mapreduce.ImportJobBase: Beginning import of fireball2021-11-26 00:29:00,658 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address2021-11-26 00:29:00,888 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar2021-11-26 00:29:01,629 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps2021-11-26 00:29:01,795 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:80322021-11-26 00:29:02,351 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/nosql/.staging/job_1637879956716_00012021-11-26 00:29:08,639 INFO db.DBInputFormat: Using read commited transaction isolation2021-11-26 00:29:08,639 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN("id"), MAX("id") FROM "fireball"2021-11-26 00:29:08,642 INFO db.IntegerSplitter: Split size: 4; Num splits: 4 from: 1 to: 202021-11-26 00:29:08,711 INFO mapreduce.JobSubmitter: number of splits:42021-11-26 00:29:09,068 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1637879956716_00012021-11-26 00:29:09,069 INFO mapreduce.JobSubmitter: Executing with tokens: []2021-11-26 00:29:09,362 INFO conf.Configuration: resource-types.xml not found2021-11-26 00:29:09,363 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.2021-11-26 00:29:09,663 INFO impl.YarnClientImpl: Submitted application application_1637879956716_00012021-11-26 00:29:09,725 INFO mapreduce.Job: The url to track the job: http://nosql:8088/proxy/application_1637879956716_0001/2021-11-26 00:29:09,726 INFO mapreduce.Job: Running job: job_1637879956716_00012021-11-26 00:29:21,029 INFO mapreduce.Job: Job job_1637879956716_0001 running in uber mode : false2021-11-26 00:29:21,030 INFO mapreduce.Job: map 0% reduce 0%2021-11-26 00:29:39,211 INFO mapreduce.Job: map 25% reduce 0%2021-11-26 00:29:42,271 INFO mapreduce.Job: map 50% reduce 0%2021-11-26 00:29:43,283 INFO mapreduce.Job: map 75% reduce 0%2021-11-26 00:29:44,290 INFO mapreduce.Job: map 100% reduce 0%2021-11-26 00:29:44,297 INFO mapreduce.Job: Job job_1637879956716_0001 completed successfully2021-11-26 00:29:44,380 INFO mapreduce.Job: Counters: 34File System CountersFILE: Number of bytes read=0FILE: Number of bytes written=1124332FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=398HDFS: Number of bytes written=950HDFS: Number of read operations=24HDFS: Number of large read operations=0HDFS: Number of write operations=8HDFS: Number of bytes read erasure-coded=0Job CountersKilled map tasks=1Launched map tasks=4Other local map tasks=4Total time spent by all maps in occupied slots (ms)=70079Total time spent by all reduces in occupied slots (ms)=0Total time spent by all map tasks (ms)=70079Total vcore-milliseconds taken by all map tasks=70079Total megabyte-milliseconds taken by all map tasks=71760896Map-Reduce FrameworkMap input records=20Map output records=20Input split bytes=398Spilled Records=0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=575CPU time spent (ms)=3940Physical memory (bytes) snapshot=634052608Virtual memory (bytes) snapshot=10745094144Total committed heap usage (bytes)=251920384Peak Map Physical memory (bytes)=159793152Peak Map Virtual memory (bytes)=2686885888File Input Format CountersBytes Read=0File Output Format CountersBytes Written=9502021-11-26 00:29:44,399 INFO mapreduce.ImportJobBase: Transferred 950 bytes in 42,7384 seconds (22,2283 bytes/sec)2021-11-26 00:29:44,403 INFO mapreduce.ImportJobBase: Retrieved 20 records. - Verify correctness
12345678910111213141516nosql@nosql:~$ hdfs dfs -ls /user/nosqlFound 1 itemsdrwxr-xr-x - nosql hadoopuser 0 2021-11-26 00:29 /user/nosql/fireballnosql@nosql:~$ hdfs dfs -ls /user/nosql/fireballFound 5 items-rw-r--r-- 1 nosql hadoopuser 0 2021-11-26 00:29 /user/nosql/fireball/_SUCCESS-rw-r--r-- 1 nosql hadoopuser 230 2021-11-26 00:29 /user/nosql/fireball/part-m-00000-rw-r--r-- 1 nosql hadoopuser 234 2021-11-26 00:29 /user/nosql/fireball/part-m-00001-rw-r--r-- 1 nosql hadoopuser 246 2021-11-26 00:29 /user/nosql/fireball/part-m-00002-rw-r--r-- 1 nosql hadoopuser 240 2021-11-26 00:29 /user/nosql/fireball/part-m-00003nosql@nosql:~$ hdfs dfs -cat /user/nosql/fireball/part-m-000001,2021-11-17,2.4,0.086,6.8,S,119.1,E,35.0,23.02,2021-11-08,3.3,0.11,33.8,S,7.7,W,36.0,null3,2021-10-28,3.0,0.1,4.1,S,138.7,W,35.2,null4,2021-10-21,3.7,0.13,51.5,N,51.4,E,30.0,15.95,2021-10-20,6.0,0.19,13.8,N,140.4,W,28.0,null - Use
-m,–num-mappersargument to usenmap tasks to import in parallel
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081nosql@nosql:~$ sqoop import -connect 'jdbc:postgresql://127.0.0.1:5432/nosql' --username 'pgsuperuser' --password 'pgsuperuserpass' --table 'fireball' --target-dir 'fireball_single' -m 1Warning: /usr/lib/sqoop/../hbase does not exist! HBase imports will fail.Please set $HBASE_HOME to the root of your HBase installation.Warning: /usr/lib/sqoop/../hcatalog does not exist! HCatalog jobs will fail.Please set $HCAT_HOME to the root of your HCatalog installation.Warning: /usr/lib/sqoop/../accumulo does not exist! Accumulo imports will fail.Please set $ACCUMULO_HOME to the root of your Accumulo installation.Warning: /usr/lib/sqoop/../zookeeper does not exist! Accumulo imports will fail.Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.2021-11-26 00:33:39,978 INFO sqoop.Sqoop: Running Sqoop version: 1.4.72021-11-26 00:33:40,053 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.2021-11-26 00:33:40,242 INFO manager.SqlManager: Using default fetchSize of 10002021-11-26 00:33:40,242 INFO tool.CodeGenTool: Beginning code generation2021-11-26 00:33:40,877 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM "fireball" AS t LIMIT 12021-11-26 00:33:40,952 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoopNote: /tmp/sqoop-nosql/compile/fee9cf75959d827ad5b17127d7d4a111/fireball.java uses or overrides a deprecated API.Note: Recompile with -Xlint:deprecation for details.2021-11-26 00:33:43,752 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-nosql/compile/fee9cf75959d827ad5b17127d7d4a111/fireball.jar2021-11-26 00:33:43,775 WARN manager.PostgresqlManager: It looks like you are importing from postgresql.2021-11-26 00:33:43,781 WARN manager.PostgresqlManager: This transfer can be faster! Use the --direct2021-11-26 00:33:43,782 WARN manager.PostgresqlManager: option to exercise a postgresql-specific fast path.2021-11-26 00:33:43,789 INFO mapreduce.ImportJobBase: Beginning import of fireball2021-11-26 00:33:43,790 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address2021-11-26 00:33:44,020 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar2021-11-26 00:33:44,790 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps2021-11-26 00:33:44,961 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:80322021-11-26 00:33:45,521 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/nosql/.staging/job_1637879956716_00022021-11-26 00:33:48,130 INFO db.DBInputFormat: Using read commited transaction isolation2021-11-26 00:33:48,194 INFO mapreduce.JobSubmitter: number of splits:12021-11-26 00:33:48,479 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1637879956716_00022021-11-26 00:33:48,481 INFO mapreduce.JobSubmitter: Executing with tokens: []2021-11-26 00:33:48,786 INFO conf.Configuration: resource-types.xml not found2021-11-26 00:33:48,787 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.2021-11-26 00:33:48,884 INFO impl.YarnClientImpl: Submitted application application_1637879956716_00022021-11-26 00:33:48,927 INFO mapreduce.Job: The url to track the job: http://nosql:8088/proxy/application_1637879956716_0002/2021-11-26 00:33:48,927 INFO mapreduce.Job: Running job: job_1637879956716_00022021-11-26 00:33:58,120 INFO mapreduce.Job: Job job_1637879956716_0002 running in uber mode : false2021-11-26 00:33:58,121 INFO mapreduce.Job: map 0% reduce 0%2021-11-26 00:34:05,246 INFO mapreduce.Job: map 100% reduce 0%2021-11-26 00:34:05,254 INFO mapreduce.Job: Job job_1637879956716_0002 completed successfully2021-11-26 00:34:05,355 INFO mapreduce.Job: Counters: 33File System CountersFILE: Number of bytes read=0FILE: Number of bytes written=281090FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=87HDFS: Number of bytes written=950HDFS: Number of read operations=6HDFS: Number of large read operations=0HDFS: Number of write operations=2HDFS: Number of bytes read erasure-coded=0Job CountersLaunched map tasks=1Other local map tasks=1Total time spent by all maps in occupied slots (ms)=4445Total time spent by all reduces in occupied slots (ms)=0Total time spent by all map tasks (ms)=4445Total vcore-milliseconds taken by all map tasks=4445Total megabyte-milliseconds taken by all map tasks=4551680Map-Reduce FrameworkMap input records=20Map output records=20Input split bytes=87Spilled Records=0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=52CPU time spent (ms)=890Physical memory (bytes) snapshot=153124864Virtual memory (bytes) snapshot=2685317120Total committed heap usage (bytes)=62980096Peak Map Physical memory (bytes)=153124864Peak Map Virtual memory (bytes)=2685317120File Input Format CountersBytes Read=0File Output Format CountersBytes Written=9502021-11-26 00:34:05,378 INFO mapreduce.ImportJobBase: Transferred 950 bytes in 20,5498 seconds (46,2293 bytes/sec)2021-11-26 00:34:05,382 INFO mapreduce.ImportJobBase: Retrieved 20 records.1234567891011121314151617181920212223242526272829303132nosql@nosql:~$ hdfs dfs -ls -R /userdrwxr-xr-x - nosql hadoopuser 0 2021-11-26 00:33 /user/nosqldrwxr-xr-x - nosql hadoopuser 0 2021-11-26 00:29 /user/nosql/fireball-rw-r--r-- 1 nosql hadoopuser 0 2021-11-26 00:29 /user/nosql/fireball/_SUCCESS-rw-r--r-- 1 nosql hadoopuser 230 2021-11-26 00:29 /user/nosql/fireball/part-m-00000-rw-r--r-- 1 nosql hadoopuser 234 2021-11-26 00:29 /user/nosql/fireball/part-m-00001-rw-r--r-- 1 nosql hadoopuser 246 2021-11-26 00:29 /user/nosql/fireball/part-m-00002-rw-r--r-- 1 nosql hadoopuser 240 2021-11-26 00:29 /user/nosql/fireball/part-m-00003drwxr-xr-x - nosql hadoopuser 0 2021-11-26 00:34 /user/nosql/fireball_single-rw-r--r-- 1 nosql hadoopuser 0 2021-11-26 00:34 /user/nosql/fireball_single/_SUCCESS-rw-r--r-- 1 nosql hadoopuser 950 2021-11-26 00:34 /user/nosql/fireball_single/part-m-00000nosql@nosql:~$ hdfs dfs -cat /user/nosql/fireball_single/part-m-000001,2021-11-17,2.4,0.086,6.8,S,119.1,E,35.0,23.02,2021-11-08,3.3,0.11,33.8,S,7.7,W,36.0,null3,2021-10-28,3.0,0.1,4.1,S,138.7,W,35.2,null4,2021-10-21,3.7,0.13,51.5,N,51.4,E,30.0,15.95,2021-10-20,6.0,0.19,13.8,N,140.4,W,28.0,null6,2021-10-20,2.0,0.073,59.0,N,154.3,E,31.4,27.57,2021-09-29,13.7,0.4,53.9,N,148.0,W,28.0,21.28,2021-09-06,3.1,0.11,2.1,S,111.8,W,26.0,13.69,2021-07-30,14.6,0.42,7.8,S,90.1,E,63.0,null10,2021-07-29,3.7,0.13,42.4,N,98.4,E,26.4,14.711,2021-07-07,3.3,0.11,null,null,null,null,null,null12,2021-07-05,74.0,1.8,44.3,N,164.2,W,43.4,15.713,2021-06-09,2.3,0.082,17.9,S,55.3,W,null,null14,2021-05-16,3.8,0.13,52.1,S,171.2,W,37.0,null15,2021-05-06,2.1,0.076,34.7,S,141.0,E,31.0,26.616,2021-05-02,2.5,0.089,12.3,N,43.4,W,null,null17,2021-04-13,2.1,0.076,26.8,N,79.1,W,44.4,14.118,2021-04-02,13.7,0.4,71.2,N,106.7,E,40.0,null19,2021-03-06,14.1,0.41,48.6,S,90.4,E,31.1,null20,2021-03-05,3.9,0.13,81.1,S,141.1,E,32.5,null
copyFromLocal command|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
nosql@nosql:~$ hdfs dfs -ls /user/nosql Found 2 items drwxr-xr-x - nosql hadoopuser 0 2021-11-26 00:29 /user/nosql/fireball drwxr-xr-x - nosql hadoopuser 0 2021-11-26 00:34 /user/nosql/fireball_single nosql@nosql:~$ hdfs dfs -copyFromLocal /home/nosql/Pulpit/nosql2/hadoop_hdfs/fireball_data.csv nosql@nosql:~$ hdfs dfs -ls /user/nosql Found 3 items drwxr-xr-x - nosql hadoopuser 0 2021-11-26 00:29 /user/nosql/fireball -rw-r--r-- 1 nosql hadoopuser 1124 2021-11-26 00:38 /user/nosql/fireball_data.csv drwxr-xr-x - nosql hadoopuser 0 2021-11-26 00:34 /user/nosql/fireball_single nosql@nosql:~$ hdfs dfs -cat /user/nosql/fireball_data.csv date,energy,impact-e,lat,lat-dir,lon,lon-dir,alt,vel 2021-11-17 15:53:21,2.4,0.086,6.8,S,119.1,E,35.0,23.0 2021-11-08 05:28:28,3.3,0.11,33.8,S,7.7,W,36,null 2021-10-28 09:10:30,3.0,0.1,4.1,S,138.7,W,35.2,null 2021-10-21 10:32:02,3.7,0.13,51.5,N,51.4,E,30,15.9 2021-10-20 08:41:50,6.0,0.19,13.8,N,140.4,W,28,null 2021-10-20 00:43:57,2.0,0.073,59.0,N,154.3,E,31.4,27.5 2021-09-29 10:50:59,13.7,0.4,53.9,N,148.0,W,28.0,21.2 2021-09-06 17:55:42,3.1,0.11,2.1,S,111.8,W,26.0,13.6 2021-07-30 08:06:34,14.6,0.42,7.8,S,90.1,E,63.0,null 2021-07-29 13:19:57,3.7,0.13,42.4,N,98.4,E,26.4,14.7 2021-07-07 13:41:14,3.3,0.11,null,null,null,null,null,null 2021-07-05 03:46:24,74,1.8,44.3,N,164.2,W,43.4,15.7 2021-06-09 05:43:59,2.3,0.082,17.9,S,55.3,W,null,null 2021-05-16 15:51:08,3.8,0.13,52.1,S,171.2,W,37.0,null 2021-05-06 05:54:27,2.1,0.076,34.7,S,141.0,E,31.0,26.6 2021-05-02 14:12:49,2.5,0.089,12.3,N,43.4,W,null,null 2021-04-13 02:16:47,2.1,0.076,26.8,N,79.1,W,44.4,14.1 2021-04-02 15:52:58,13.7,0.4,71.2,N,106.7,E,40.0,null 2021-03-06 08:43:06,14.1,0.41,48.6,S,90.4,E,31.1,null 2021-03-05 13:50:01,3.9,0.13,81.1,S,141.1,E,32.5,null |
Displays first kilobyte of the file to stdout.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
nosql@nosql:~$ hdfs dfs -head fireball_data.csv date,energy,impact-e,lat,lat-dir,lon,lon-dir,alt,vel 2021-11-17 15:53:21,2.4,0.086,6.8,S,119.1,E,35.0,23.0 2021-11-08 05:28:28,3.3,0.11,33.8,S,7.7,W,36,null 2021-10-28 09:10:30,3.0,0.1,4.1,S,138.7,W,35.2,null 2021-10-21 10:32:02,3.7,0.13,51.5,N,51.4,E,30,15.9 2021-10-20 08:41:50,6.0,0.19,13.8,N,140.4,W,28,null 2021-10-20 00:43:57,2.0,0.073,59.0,N,154.3,E,31.4,27.5 2021-09-29 10:50:59,13.7,0.4,53.9,N,148.0,W,28.0,21.2 2021-09-06 17:55:42,3.1,0.11,2.1,S,111.8,W,26.0,13.6 2021-07-30 08:06:34,14.6,0.42,7.8,S,90.1,E,63.0,null 2021-07-29 13:19:57,3.7,0.13,42.4,N,98.4,E,26.4,14.7 2021-07-07 13:41:14,3.3,0.11,null,null,null,null,null,null 2021-07-05 03:46:24,74,1.8,44.3,N,164.2,W,43.4,15.7 2021-06-09 05:43:59,2.3,0.082,17.9,S,55.3,W,null,null 2021-05-16 15:51:08,3.8,0.13,52.1,S,171.2,W,37.0,null 2021-05-06 05:54:27,2.1,0.076,34.7,S,141.0,E,31.0,26.6 2021-05-02 14:12:49,2.5,0.089,12.3,N,43.4,W,null,null 2021-04-13 02:16:47,2.1,0.076,26.8,N,79.1,W,44.4,14.1 2021-04-02 15:52:58,13.7,0.4,71.2,N,106.7,E,40.0,null 2021-03-nosql@nosql:~$ |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ ls -l razem 16 -rw-rw-r-- 1 nosql hadoopuser 1124 lis 25 22:04 fireball_data.csv -rw-rw-rw- 1 nosql hadoopuser 916 lis 25 23:35 fireball_data_from_postgresql.csv -rw-rw-r-- 1 nosql hadoopuser 1609 lis 25 21:47 fireball_data.json -rwxrw-r-- 1 nosql hadoopuser 82 lis 25 21:53 json2csv nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ hdfs dfs -copyToLocal /user/nosql/fireball/part-m-00000 nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ ls -l razem 20 -rw-rw-r-- 1 nosql hadoopuser 1124 lis 25 22:04 fireball_data.csv -rw-rw-rw- 1 nosql hadoopuser 916 lis 25 23:35 fireball_data_from_postgresql.csv -rw-rw-r-- 1 nosql hadoopuser 1609 lis 25 21:47 fireball_data.json -rwxrw-r-- 1 nosql hadoopuser 82 lis 25 21:53 json2csv -rw-r--r-- 1 nosql hadoopuser 230 lis 26 00:42 part-m-00000 nosql@nosql:~/Pulpit/nosql2/hadoop_hdfs$ cat part-m-00000 1,2021-11-17,2.4,0.086,6.8,S,119.1,E,35.0,23.0 2,2021-11-08,3.3,0.11,33.8,S,7.7,W,36.0,null 3,2021-10-28,3.0,0.1,4.1,S,138.7,W,35.2,null 4,2021-10-21,3.7,0.13,51.5,N,51.4,E,30.0,15.9 5,2021-10-20,6.0,0.19,13.8,N,140.4,W,28.0,null |