
 Informations presented on this page may be incomplete or outdated. You can find the most up-to-date version reading my book NoSQL. Theory and examples
Informations presented on this page may be incomplete or outdated. You can find the most up-to-date version reading my book NoSQL. Theory and examples
Although this tutorial is about NoSQL, we start our story from relational pattern. This could be confusing, but we do this because
- Remember that term NoSQL means Not only SQL but No SQL. In this context, term SQL refers not exactly to SQL as a language but rather to the whole ecosystem where SQL has existed for the last decades and will exist in the foreseeable feature: the relational databases. We are not saying We don't need SQL (and relational databases). Instead we say Because sometimes relational model is not enough, we have to change it in some aspects.
- If there are situations where relational databases aren’t the best match for our business problem, we should know why this pattern is not suitable for us and what solution(s) we can choose instead.
- Relational model is well known and has very good support in terms of software, documentation, specialist - before you will resign from this patter, you should be sure what you are doing.
- To correctly understand NoSQL databases and all pros and cons we need some reference - in this case we will compare them with one mode we know best - the relational model.
In this part we cover the following topics
- Pre-relational era
- Relational era
- Object-oriented era
- Relational pattern
- Nowadays (post-relational) databases trends
Relational databases for almost 30 years were so dominant in database market that no one remember about it's difficult birth time. It's hard to believe, that big players on computer market were very sceptic to this model. Searching for an answer, why this has happened, we have to go back to the late 1950s.
Very general definition of database we can find in Wikipedia is: database is an organized collection of data. Collecting of data seems to be a vital an integral factor in the development of human civilization and technology. First collections have a strongly enforced by physical limitations structure: it's enough to think about books (especially dictionaries and encyclopedias) and libraries. Industrial revolution brought us a set of new tools we can use. We can see the genesis of todays digital database in the adoption of punched cards and other physical media that could store information in a form that could be processed mechanically. We know from the computer science history, that in the 19th century loom cards were used to program fabric looms to generate complex fabric patterns. Next, based on loom cards idea, Hollerith tabulating machines used punched cards to process the US. census in 1890. The introduction of the term database coincided with the availability of direct-access storage (disks and drums) that direct high-speed access to individual records became possible.
Relatively quickly found out that
- concurrent access or data changes required sophisticated code in order to avoid logical or physical data corruption;
- database handling code was repeated from one application to the other;
- any errors we can make in application data handling code while this code was ported from one application to the other led inevitably to corrupted data;
- not all optimization techniques and algorithms could be easily ported in each application.
Therefore, it became quite natural to do all of this stuff once and use many times for different databases. This way database handling logic was moved from the application to the intermediate layer - the Database Management System, or DBMS.
Unfortunately, early database systems, from performance reasons and lack of any other preceding experiences and premises, enforced both
- A schema - a definition of the structure of the data within the database. The system to deliver adequate performance enforced data representation so it was fine-tuned to the underlying access mechanisms.
- An access path (a way we get the data) by a fixed sequence of navigating steps from one record to another.
The databases systems of that time are named navigational. The two main early navigational data models were the hierarchical model(IBM's IMS system), and the network model (CODASYL).
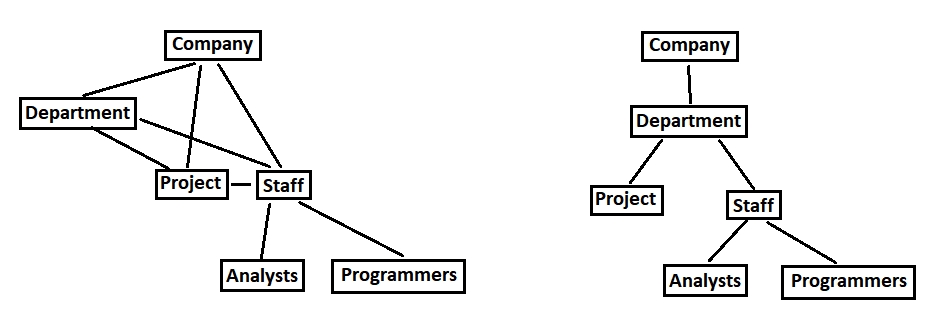
|
| Network and hierarchical database models |
As we can see, in hierarchical model to get from Company to Project we have to follow the path Company-Department-Project.
We can say that DBMS of the day were designed by manufacturers, not users. All models, data structures, hardware and software were very tightly connected to gain desirable performance.
In the late 1960s, Edgar Codd was working at an IBM laboratory in San Jose, California. He was very familiar with the databases of the day, and he noticed all the pros and, what was important, cons about their design. In particular, he noticed that
- Existing databases mixed logical and physical implementations. The representation of data in existing databases matched the format of the physical storage in the database, rather than a logical representation of the data that could be comprehended by a nontechnical user.
- Existing databases lacked a theoretical foundation. There were no common formal structures and logical operations we could do.
- Based on arbitrary representations that did not ensure logical consistency it wasn't possible to deal with failures and consistencies problems.
- As a consequence of a previous, existing databases were too hard to use. Databases of the day could only be accessed by people with specialized technical and programming skills which was very distant from business applications.
Codd published an internal IBM paper outlining his ideas about a more formalized model for database systems, which then led to his famous 1970 paper A Relational Model of Data for Large Shared Data Banks.
Even big players as IBM was skeptical and questioned the possibility of creation Codd's relational databases which could deliver adequate performance. However in 1974 IBM initiate a research program to develop a prototype relational database system called System R. System R was the first implementation of SQL. It was also the first system to demonstrate that a relational database management system could provide good transaction processing performance. System R's first customer was Pratt & Whitney in 1977.
The same time, Mike Stonebraker at Berkeley started work on a database system that eventually was called INGRES. INGRES was also relational, but it used a non-SQL query language called QUEL.
Another person worth to mention is Larry Ellison who was familiar both with Codd’s work and with System R, and, what is more important, he believed that relational databases represented the future of database technology. In 1977, Ellison founded the company that would eventually become Oracle Corporation and which would release the first commercially successful relational database system.
During the succeeding decades many new database systems (system as a software not conception) were introduced. These include Sybase, Informix, DB2, Microsoft SQL Server and MySQL. While all of them differentiate in terms of performance, availability, functionality, or economy, they all share three key principles: Codd’s relational model, the SQL language, and the ACID transaction model.
Another big step done by databases was caused by introduction of object-oriented programming. This paradigm binds data with logic. In traditional, procedural, programming languages, data and logic were essentially separate. Procedures would load and manipulate data within their logic, but the procedure itself did not contain the data in any meaningful way. Object-oriented programming merged attributes and behaviors into a single object. All the details relevant to a logical unit of work would be stored within the one class or directly linked to that class. This was a source of discontency among developers who were forced to work with the object-oriented representations of their data within their programs and the relational representation within the database. It is difficult not to agree with the following relevant comparison: A relational database is like a garage that forces you to take your car apart and store the pieces in little drawers.
When an object was stored into or retrieved from a relational database, multiple SQL operations would be required to convert from the object oriented representation to the relational representation. This was cumbersome for the programmer and could lead to performance or reliability issues.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
Storing an object in an RDBMS requires multiple SQL operations. TABLES: --------------------- Invoice <= SQL => --------------------- OBJECTS: PK, FK InvoiceNumber ------------------- FK CustomerNumber Customer --------------------- ------------------- +CustomerNumber +CustomerName --------------------- +CustomerLocation CustomerDetails +Invoices[] <= SQL => --------------------- ------------------- PK CustomerNumber +create() CustomerName +addInvoice() CustomerLocation +addItemToInvoice() --------------------- ------------------- --------------------- InvoiceDetails <= SQL => --------------------- PK InvoiceNumber PK InvoiceItem ItemName ItemQuantity ItemPrice --------------------- |
It was clear that an Object Oriented Database Management System (OODBMS) was better suited to meet the demands of modern applications. An OODBMS would store program objects directly without normalization, and would allow applications to load and store their objects easily. Object oriented representation seems to be natural but is inherently non-relational; indeed, the representation of data matched more closely to the network databases of the previous era like CODASYL. OODBMS offered the advantages to the application developer, but forgot about those who wished to consume information for business purposes. This could be the reason that OODBMS systems had completely failed to gain market share. We have to remember that databases don’t exist to make programmers life simpler. They represent significant assets that must be accessible to those who want to mine the information for decision making and business intelligence. By implementing a data model that was only understandable and could be used by the programmer, and ignoring the business user of a usable SQL interface, the OODBMS failed to gain support outside programmers world.
Relational pattern is an example of the row-store design pattern. Technically speaking, this type of databases store their data in a uniform object called a row. Rows consist of a fixed number of data fields that are associated with a column name and a single data type. Rows are always added, changed and deleted as atomic units (a unit of work that’s independent of any other adds, changes or deletes while this operation is in progress). This type of databases is commonly known under then RDBMS or SQL database name.
The most descriptive features of this pattern are
- The rows you insert comprise your tables in an RDBMS.
- Tables can be related to other tables and data relationships are also stored in tables.
- The entire table, with all column definitions and their data types, must be created before the first row is inserted into the table.
- Columns must have unique names within a table and a single data type which is created when a table is first defined.
- To increase access speed an indexes are created on tables that have many rows.
- We get data in usable form by selecting all related rows from different tables with JOIN statements.
Key concepts of the relational model are
- Tuples. In mathematics a tuple is a finite ordered list (sequence) of elements. An n-tuple is a finite ordered list (sequence) of n elements, where n is a non-negative integer. There is only one 0-tuple, an empty sequence. An n-tuple is defined inductively using the construction of an ordered pair. In computer science, tuples come in many forms. In a relational databases system, a tuple corresponds to a row, and an attribute (tuple's element) to a column value.
Tuples examples taken from the Swift programming language
12345// Tuple of type (Int, String)let warning = (123, "This is a critical warning")var (currentMessageCode, currentMessageText) = warningprint ("Message text " + currentMessageText)print ("Message text \(currentMessageText)")If we don't care about the first element of a tuple, we can write it as
1(_, currentMessageText) = warningWe can also use index numbers starting at zero to get tuple's element
1print ("Message text " + warning.1)To make our code more readable, we can name the individual elements in a tuple when the tuple is defined
1234let alert = (messageCode: 456, messageText: "This is an alert")let info = (messageCode: 456, messageText: "This is an information you can simply ignore")print ("Message text " + alert.messageText) - Relation(s). A relation is a collection of distinct tuples and corresponds to a table in relational database system.
- Constraints. A constraints enforces consistency of the database. Key constraints are used to identify tuples and relationships between tuples.
- Operations. Operations are actions we can do on relations: joins, projections, unions, and so on. Operations always return relations which means that a query on a table returns data in a tabular format.
What is interesting, relational model defines few levels of conformance which are described under the normal forms names. Now we will discuss first three of them to get the idea what they are for. Yes, in this tutorial we will be talking about NoSQL but I want we have a good understanding of relational legacy to not blindly follow NoSQL trend.
In practical applications, we will see 1NF, 2NF, and 3NF. Other forms: BCNF or 3.5NF, 4NF and 5NF are not so often see so we will not discussed it, as first three are enough to get the idea.
- First normal form (1NF) is a property of a relation in a relational database. A relation is in first normal form if and only if the domain of each attribute contains only atomic (indivisible) values, and the value of each attribute contains only a single value from that domain. Moreover, for every row there should exists primary key -- one or more columns uniquely identifying that row.
First normal form (1NF) sets the very basic rules for an organized database and enforces these criteria:
- Eliminate repeating groups in individual tables.
- Create a separate table for each set of related data.
- Identify each set of related data with a primary key
- Second normal form (2NF) In addition to the primary key, the relation may contain other candidate keys (candidate key: a minimum set of attributes of the relationship, uniquely identifying each tuple of this relation).
A candidate key of a relation is a set of attributes such that
- the relation does not have two distinct tuples (i.e. rows or records in common database language) with the same values for these attributes (which means that the set of attributes is a superkey)
- there is no proper subset of these attributes for which (1) holds (which means that the set is minimal).
The constituent attributes are called prime attributes. Conversely, an attribute that does not occur in ANY candidate key is called a non-prime attribute.
To have relations in 2NF, it is necessary to establish that no non-prime attributes have part-key dependencies on any of candidate keys. Any functional dependency on part of any candidate key is a violation of 2NF.
We have to remember that normalization guidelines are cumulative. For a database to be in 2NF, it must first fulfill all the criteria of a 1NF database; to be in 3NF, it mus be in 2NF , etc.
Other words, second normal form (2NF) addresses the concept of removing duplicative data
- Meet all the requirements of the first normal form.
- Remove subsets of data that apply to multiple rows of a table and place them in separate tables.
- Create relationships between these new tables and their predecessors through the use of foreign keys.
- Third normal form (3NF) Third normal form is a normal form that is used in normalizing a database design to reduce the duplication of data and ensure referential integrity by ensuring that all the attributes in a table are determined only by the candidate keys of that relation and not by any non-prime attributes.
Other words, third normal form (3NF) goes one step further in the concept of removing duplicative data: remove columns that are not dependent upon the primary key
- Meet all the requirements of the second normal form.
- Remove columns that are not dependent upon the primary key (Each column must depend directly on the primary key and nothing else than primary key).
A well known phrase related to 3NF is [Every] non-key [attribute] must provide a fact about the key, the whole key, and nothing but the key, so help me Codd.- Requiring existence of the key ensures that the table is in 1NF.
- Requiring that non-key attributes be dependent on the whole key ensures 2NF.
- Requiring that non-key attributes be dependent on nothing but the key ensures 3NF.
While this phrase is a useful mnemonic, the fact that it only mentions a single key means it defines some necessary but not sufficient conditions to satisfy the 2nd and 3rd Normal Forms. Both 2NF and 3NF are concerned equally with all candidate keys of a table and not just any one key.
Let's illustrate this with an example. We will use a very common case related to invoice (compare Three Normal Forms Database Tutorial for a more elaborated example).
- Initial case
1234567Table: invoiceInvoice Customer Customer Customer Itemnumber number name location (name, quantity, price)1 10 Dart Vader Star Destroyer {lightsaber, 1, 100}, {black cloak, 2, 50}, {air filter, 10, 2}2 30 C3PO Tatooine {battery, 1, 25}3 20 Luke Skywalker Naboo {lightsaber, 5, 75}, {belt, 1, 5}4 30 C3PO Tatooine {wires, 1, 10} - 1NF
1NF is violated because- we have no atomic values ({lightsaber, 1, 100})
- and the value of each attribute contains not only a single value (multiple {...} elements).
We can fix this with the following data reorganization
12345678910111213141516171819Table: invoiceInvoicenumber=======123Table: invoice_detailsInvoice Invoice Customer Customer Customer Item Item Itemnumber item number name location name quantity price================================================================================================1 1 10 Dart Vader Star Destroyer lightsaber 1 1001 2 10 Dart Vader Star Destroyer black cloak 2 501 3 10 Dart Vader Star Destroyer air filter 10 22 1 30 C3PO Tatooine battery 1 253 1 20 Luke Skywalker Naboo lightsaber 5 753 2 20 Luke Skywalker Naboo belt 1 54 1 30 C3PO Tatooine wires 1 10 - 2NF
2NF is violated because- we have a subset of data that apply to multiple rows of a table.
In this case we have the following candidate key: {Invoice number, Invoice item}. The customer informations (number, name and location) is dependent on a proper subset of it: Invoice number.
The trouble with that is that the customer informations (number, name and location) goes with each line on the invoice. This cause redundant data, with it's inherent overhead and difficult modifications. Second form normalization requires we place the customer information in the separate (invoice) table.
We can fix this with the following data reorganization
1234567891011121314151617181920Table: invoiceInvoice Customer Customer Customernumber number name location===========================================1 10 Dart Vader Star Destroyer2 30 C3PO Tatooine3 20 Luke Skywalker Naboo4 30 C3PO TatooineTable: invoice_detailsInvoice Invoice Item Item Itemnumber item name quantity price================================================1 1 lightsaber 1 1001 2 black cloak 2 501 3 air filter 10 22 1 battery 1 253 1 lightsaber 5 753 2 belt 1 54 1 wires 1 10 - we have a subset of data that apply to multiple rows of a table.
- 3NF
3NF is violated because- we have columns in the invoice table that are not dependent upon the primary key.
In this case some customer informations depends not only on the key but also on the other attributes. For example Customer_name depends (also) on Customer_number - whenever we see Customer_number=10 it implies Customer_name="Dart Vader". The trouble with that is that the customer informations (number, name and location), located in the invoice table, cause data redundancy if several invoices are for the same customer (see C3PO). It would also cause a problems when the customer changes some of them (for example: location). Third form normalization requires the customer informations go in a separate table with its own key (Customer number), with only the customer number in the invoice table.
We can fix this with the following data reorganization
12345678910111213141516171819202122232425262728Table: invoiceInvoice Customernumber number=================1 102 303 204 30Table: customer_detailsCustomer Customer Customernumber name location==================================10 Dart Vader Star Destroyer20 Luke Skywalker Naboo30 C3PO TatooineTable: invoice_detailsInvoice Invoice Item Item Itemnumber item name quantity price================================================1 1 lightsaber 1 1001 2 black cloak 2 501 3 air filter 10 22 1 battery 1 253 1 lightsaber 5 753 2 belt 1 54 1 wires 1 10 - we have columns in the invoice table that are not dependent upon the primary key.
- Atomic. The transaction can not be divided - either all the statements in the transaction are applied to the database or none are.
- Consistent. The database remains in a consistent state before and after transaction execution.
- Isolated. While multiple transactions can be executed by one or more users simultaneously, one transaction should not see the effects of other in-progress transactions.
- Durable. Once a transaction is saved (committed) to the database, its changes are expected to persist even if there is a failure of operating system or hardware.
- ACID transactions at the database level makes development and usage easier.
- Most SQL code is portable to other SQL databases.
- Typed columns and constraints helps validate data before it’s added to the database which increase consistency of the data stored in database.
- Build in mechanism like views or roles prevents data to be changed or viewed by unauthorized users.
- ACID transactions may block system for a short time which may be unacceptable.
- The object-relational mapping is possible but can be complex and add one more intermediate layer.
- RDBMSs don’t scale out. Sharding over many servers can be done but requires new or tuned application code and will be operationally inefficient.
- It is difficult to store high-variability data in tables.
- It is difficult to store data in real time and make real time processing.
- Google and Hadoop (around 2005)
- Cloud computing (around 2008)
- Document databases (around 2004, AJAX)
- The NewSQL as the answer for cloud deployment, mobile presence, social networking, and the Internet of Things demands.
The relational model does not itself define the way in which the database handles concurrent data change requests named transactions. To ensure consistency and integrity of data an ACID transaction model is used and became de facto the standard for all serious relational database implementations. An ACID transaction should be
From one side ACID along with relations is the source of the power of relational databases. On the other hand this is a source of serious and very difficult to overcome problems.
Codd formed thirteen rules to define what is required from a database management system in order for it to be considered relational. He did it as part of a personal campaign to prevent the vision of the original relational database from being diluted, as database vendors scrambled in the early 1980s to repackage existing products with a relational veneer.
Relational model is undoubtedly characterized by the following set of positive features
To be honest one cannot forget about negative side of relational model
Relational model is good for many tasks but not enough for all nowadays problems. Cons of this model pushed people to search for alternatives - this is how NoSQL was born.
Some of the most influential nowadays databases trends
Now we are not based on a single architectural foundation. The first platform was the mainframe, which was supported by pre-relational database systems. The second platform, client-server and early web applications, was supported by relational databases. The third platform is characterized by applications that involve cloud deployment, mobile presence, social networking, and the Internet of Things. The third platform demands a third wave of database technologies that include but are not limited to relational systems.